
Table of Contents
Last year I wrote and self-published my first technical book Hands-on Scala Programming. It has gone on to be relatively successful, selling thousands copies, both digital and physical. This blog post will explore how the process of writing and publishing Hands-on Scala went: from its inception, to writing, editing, and finally publishing in multiple formats and mediums.

About the Author: Haoyi is a software engineer, and the author of many open-source Scala tools such as the Ammonite REPL and the Mill Build Tool. If you enjoyed the contents on this blog, you may also enjoy Haoyi's book Hands-on Scala Programming
Over the past 10 years, I have been involved in the Scala community, and over time developed an ecosystem of open source libraries using Scala. These stemmed from my own personal needs: while I loved the Scala language, trying to use the existing Scala ecosystem of libraries often ended in tears, and so I wrote my own. These include:
This process took place over the better part of a decade: Scalatags was first written in 2012, Ammonite appeared in 2015, Mill appeared in 2017, OS-Lib and Requests-Scala were developed in late 2018. This development was not planned, with each library being developed to satisfy the needs of the moment, and without any long term roadmap in place. Some libraries were useful, and saw wide adoption and longevity in the community, while others failed to gain traction and fell by the wayside.
One thing interesting about my suite of libraries is how different it was from what was already out there in the Scala community. The existing Scala community was focused around two camps: ultra-high-concurrency "Reactive" architectures, and hard-core pure functional programming. Both of these styles have their advantages, but they were very much not beginner-friendly. This resulted in a situation where experts could do amazing things with Scala, but newbies were constantly tripping over stumbling blocks as they tried to learn the language.
The suite of libraries I had built was the opposite of that: simple and easy to get started with, perhaps lacking some advanced capabilities, but still robust enough you can use them to build whatever you need. For myself, these libraries were what I always wanted using Scala, and it turns out sometimes if you want something you got to do it yourself.
In June 2019, I was visiting EPFL for the Scaladays conference, and discussed with a number of people how we could make Scala simpler to learn for newcomers. Trying to get more newcomers to use my ecosystem of libraries, the "com.lihaoyi" ecosystem, was one of the topics.
The Scala ecosystem is not small. However, many would agree that there is a hole in the ecosystem around the beginner experience: much of the existing libraries and tools are catered at experts. The idea was that my "com.lihaoyi" ecosystem of libraries and tools could bridge that gap: providing a smooth ramp up experience for newbies, allowing them to learn fast and go far. Later on, if they decided they needed something more advanced, they could do so, but they should not need to struggle with advanced tools and techniques when first learning the Scala language.
Even in 2019, my "com.lihaoyi" ecosystem of libraries already existed, and worked great. Why then did I write a book? Each of my libraries worked great in isolation. Every library was mature. Every library had thorough documentation, rigorous testing, and rave reviews by its users. Each library had an interface cloned from the most popular Python libraries (Requests, Flask, etc.), ensuring a high baseline of intuitiveness and usability.
All that sounds great. But beyond that, there were significant gaps that would be encountered by a new user trying to get on board with them:
It was clear at that point that there was a book-shaped hole in the "com.lihaoyi" ecosystem. Something to provide evangelism, legitimacy, discoverability. Something to hand-hold users through not just a language or its libraries, but through using this language and these libraries to do useful things. That is the hole where Hands-on Scala Programming was meant to fill.
My initial plan was as follows:
I wrote the book concurrently with my job at Databricks. This was both a blessing and a curse. A blessing because using Scala every day at work helped focus the mind on what was important for me to teach in this book. A curse because my job at Databricks already had plenty of difficult, challenging work to do: writing a book on top of that work would prove to be incredibly exhausting.
The first thing to do was to come up with the "skeleton" of what the book would cover. My initial table of contents was as follows:
# Hands-on Scala Programming
## 1 Introduction to Scala
[ ] 1 Hands On Scala Programming
[ ] 2 Setting up
[ ] 3 Basic Scala
[ ] 4 Scala Collections
[ ] 5 Scala Scripts
## 2 Local Data Processing
[ ] 5 Fiddling with Files
[ ] 6 Spawning Subprocesses
[ ] 7 Structured Data in JSON
[ ] 8 Third-Party Modules
[ ] 9 Build Pipelines
## 3 Remote Systems
[ ] 10 Accessing APIs
[ ] 11 Scraping Websites
[ ] 12 Simple Web Servers
[ ] 13 Querying SQL Databases with Quill
## 4 Additional Topics
[ ] 14 Unit Testing with uTest
[ ] 15 Packaging and Publishing
[ ] 16 Parallel Programming with Futures
[ ] 17 Parsing Structured Text with FastParse
[ ] 18 Multi-Process Applications
This table of contents, rough as it is, clearly spells out what I want this book to be about: not about the Scala language, nor about this library or that library, but rather about accomplishing useful things using Scala. Chapters aren't demarcated by what section of the language spec they cover, or by what library they use, but by use cases: the kind of thing your boss may ask you to do.
This was a book targeted at professionals, using the language to do the kind of things someone might pay you for: scraping, API integrations, setting up servers, wrangling databases. There were already plenty of excellent books covering the minutiae of the Scala language itself, the place for Hands-on Scala Programming was to help the reader do something useful with Scala as quickly as possible, for a wide variety of "something useful"s.
This table of contents evolved significantly as the book was developed, but once I had it, the time came to fill it in.
After getting the table of contents sketched out, my next goal was to write as many chapters I could as standalone blog posts. While my blog posts aren't necessarily as polished as the chapters of a book, they serve several purposes:
Provide some milestones to work towards: publishing a new post is motivating in a way that writing in private is not
Help build an audience on my blog, which would prove valuable whenever the book is actually released
Below is a selection of new blog posts that ended up being chapters on my book:
I also pulled in some of my old blog posts that were already written long before the book was even conceived, that happened to fit into the table of contents that I had decided on.
Even as blog posts, I maintained some level of quality: a typical blog post 10-20 pages long would take me maybe 8 hours to write, spread over several days. This includes coming up with the idea, writing all the prose and example code, and several rounds of self-editing (both small-scale line-edits and large-scale re-organizations) before I considered it polished enough to publish on my blog.
Once all the blog posts were done, it took some more time to write the chapters that didn't make it as blog posts. At this point the table of contents had evolved into that shown below:
# Hands-on Scala Programming (290 pages)
## 1 Introduction to Scala (63 pages)
[x] 1 Hands On Scala Programming (4 pages)
[x] 2 Setting up (11 pages)
[x] 3 Basic Scala (24 pages)
[x] 4 Scala Collections (12 pages)
[x] 5 Implementing Common Algorithms in Scala (22 pages)
## 2 Local Data Processing (61 pages)
[x] 6 Fiddling with Files (11 pages)
[x] 7 Spawning Subprocesses (8 pages)
[x] 8 Structured Data in JSON (9 pages)
[x] 9 Parsing Structured Text with Fastparse (13 pages)
[x] 10 Building a Static Site Generator (20 pages)
## 3 Systems and Services (81 pages)
[x] 11 Multi-Process Applications (15 pages)
[x] 12 Working with HTTP JSON APIs (14 pages)
[x] 13 Scraping Websites with JSoup (12 pages)
[x] 14 Simple Web Servers and API Servers (21 pages)
[x] 15 Querying SQL Databases with Quill (19 pages)
## 4 Additional Topics (75 pages)
[x] 16 Parallel Programming with Futures (13 pages)
[x] 17 Message-based Parallelism with Actors (14 pages)
[x] 18 Static Asset Pipelines with Mill (14 pages)
[x] 19 Building a Real-time File Synchronizer (19 pages)
[x] 20 Implement your own Programming Language (15 pages)
As you can see, the set of chapters had evolved in the process of writing. Unit Testing with uTest and Packaging and Publishing were gone: I couldn't figure out a way to make them standalone chapters. New chapters Implement your own Programming Language, Building a Static Site Generator and Implementing Common Algorithms in Scala were added. I ended up covering packaging as a small part of other chapters, skipping publishing entirely, and showing unit tests via the online example code (which is all unit tested).
At this point, the basic "stuff" of the book is all there: every planned chapter has been fleshed out with multiple rounds of chapter-level self-editing. The next step was to turn this loose collection of blog posts and turn it into a coherent book.
I did not get any professional editors for my book. Instead, I opted several rounds of self review, as well as review by 20 or so friends and colleagues. The list of reviewers can be seen in the front matter of the book; on the web version, this is underneath the table of contents in the following link:
Before passing the manuscript to others, I did three full self-review passes: print out the whole book on paper, read through it and mark it up with a colored pen, and then perform the edits as a separate pass. This helped me focus on the experience of reading the book as a reader.
I completed these three passes on the following dates:
Self reviewing a 300 page technical book is simply exhausting. It's not any less tiring than trying to read a 300 technical book for the first time: sure you may be familiar with the content, but you then have to work extra hard to try and view the content from a third-party perspective. Doing it three times in a month was very difficult.
Even after spending a month doing three painstaking rounds of self review, with tons of improvements and fixes, the book still had problems. Big problems, small problems, and plenty of them. That was as expected, and it was the job the external reviewers to help to sort those out.
External review was done by a motley crew of friends, family, colleagues and acquaintances. Their level of experience varied wildly: from people a few years my junior, to folks more than twice my age. Some had years of experience using Scala, while others had never touched it. Some were web developers, some were infrastructure folks, some were compiler engineers, some weren't professional programmers at all! This diversity of backgrounds turned out to be invaluable in getting the book to a good state.
While I had people agree to review pretty early on in the process, I did not want to send them the manuscript until I had completed my own review and edits: no point wasting their time picking up issues that I can find myself! Similarly, I arranged the reviewers in two waves: one starting January 2020, one starting April 2020, with about 10 reviewers in each batch. This meant that whatever problems the first group encountered could be fixed before the second group got their hands on the manuscript, so they could find a new set of issues.
The wide diversity of reviewers was a great boon: some folks were super detail oriented and would catch tiny typos and errors, others would provide high level feedback that helped shape the overall structure. Some would focus on the code and concepts, others would nitpick my english sentence structure to hell and back. All of them contributed greatly to the version of Hands-on Scala Programming that finally ended up being published.
The whole process was pretty informal: I emailed each reviewer a PDF, and they would email me back feedback as they made their way through it. Feedback was in whatever format they were comfortable with: bullet points in an email, attached markdown files, annotated PDFs, whatever.
Not everyone who committed to being a reviewer managed to follow through: the 20 reviewers listed in the book are those that completed at least 5 chapters, and only about 10 of those reviewers completed the whole book. This is expected; they were all volunteers after all, many with more important things to do in their life than read and critique a 400 page book. The fact that many reviewers would drop out was expected and planned for, and I am grateful for any and all the feedback the reviewers gave me regardless of how far they made it.
Countless low-level fixes that went into the book during review (self and external): typos, english improvements, and so on. But perhaps the most interesting thing to discuss here is the high-level feedback I received, and the high-level changes I made.
High-level Feedback included things like:
"The book builds up to some really interesting and non-trivial stuff. Setting higher expectations from the beginning would make more people stick through till the end."
"Chapter 4: A lot of this chapter felt ponderous. Going through all of the different collection methods just isn't very interesting, even with some concrete examples."
"Web-services was my favorite section - where we've gotten past the basics, starting to do something fun, but not so advanced that I'm lost. "
" a "where do I go from here?", or a summary, or other form of conclusion could probably add a lot."
Different reviewers with different backgrounds had different opinions, which was totally expected. e.g. a web developer really liked the chapters on HTTP clients/servers while finding the chapters on parsers/interpreters boring, while the compiler engineers had the opposite opinion. Despite the contradictory opinions, the reviews helped paint a fuller picture of how people would respond to the book. The diversity of the final audience would dwarf the diversity of my 20 reviewers!
Below are some of the major changes I made in response to feedback:
People universally said that Fiddling with Files and Spawning Subprocesses were tedious and draggy, so I combined them into a single chapter 7 Files and Subprocesses
Many people gave feedback that they want to know more about what's unique about Scala, so I wrote and introduced a brand new chapter 5 Notable Scala Features
People said they wanted to understand more of what's going on, rather than just reading recipes, and so additional theoretical content was introduced in all chapters where relevant. e.g. chapter 4 Scala Collections gained some sections on structural sharing, chapter 8 Structured Data in JSON gained some sections discussing the benefits of context-bound/implicit-based data serialization
The book was re-organized from "breadth first" to a much more "depth first" manner. For example, previously we went into "basics" early in the book, like parsing in 9 Parsing Structured Text with Fastparse and scripting in 10 Building a Static Site Generator. We then re-used that code in "projects" later in the book like 20 Implement your own Programming Language and 18 Static Asset Pipelines with Mill respectively. People found it hard to remember what was covered so many chapters ago. Instead, I made Building a Static Site Generator and Static Asset Pipelines with Mill run back-to-back in chapters 9 and 10, with Parsing Structured Text with Fastparse and Implement your own Programming Language back-to-back as chapters 19 and 20, so every chain of related chapters happens sequentially as much as possible.
By the end of all the reviews and editing, the final book ended up looking like this:
# Hands-on Scala Programming (413 pages)
- Front Matter (9 pages)
## 1 Introduction to Scala (92 pages)
- 1 Hands On Scala Programming (10 pages)
- 2 Setting up (14 pages)
- 3 Basic Scala (20 pages)
- 4 Scala Collections (22 pages)
- 5 Notable Scala Features (24 pages)
## 2 Local Compute (98 pages)
- 6 Implementing Algorithms in Scala (20 pages)
- 7 Files and Subprocesses (20 pages)
- 8 JSON and Binary Data Serialization (16 pages)
- 9 Self-Contained Scala Scripts (16 pages)
- 10 Static Build Pipelines (24 pages)
## 3 Systems and Services (104 pages)
- 11 Scraping Websites (16 pages)
- 12 Working with HTTP APIs (18 pages)
- 13 Parallel Programming with Futures (22 pages)
- 14 Simple Web Servers and API Servers (26 pages)
- 15 Querying SQL Databases (20 pages)
## 4 Program Design (107 pages)
- 16 Message-based Parallelism with Actors (20 pages)
- 17 Multi-Process Applications (18 pages)
- 18 Building a Real-time File Synchronizer (18 pages)
- 19 Parsing Structured Text (22 pages)
- 20 Implement your own Programming Language (26 pages)
At this point, you can see the structure is greatly improved. Where previously the chapter sizes varied wildly, now they are all very even at around 20 pages a piece. Now related chapters are all grouped together in a much more sensible way, with consecutive chapters building upon each other rapidly towards larger and more sophisticated projects.
Throughout all this writing, I also maintained a build pipeline that would turn my input markdown files into static HTML web pages, and finally into print-ready PDFs. The basic concepts involved in doing so are explained in chapter 10 Static Build Pipelines, and the code involved is open sourced here:
The basic idea is to take markdown, render it into static HTML/CSS web pages, and then use Chrome (via the Puppeteer library) to turn the HTML/CSS into PDFs. I still needed to do minor post-processing on the PDFs, e.g. to figure out page numbers which are only known after conversion to PDF, and for that I used the Apache PDFBox Java library.
While input markdown is convenient to write, having a HTML intermediary has many advantages. From my history of web development, I know how to make HTML/CSS look however I want it to look. While I could conceivably generate PDFs and style them manually using Apache PDFBox, it was much easier to get everything looking good as a static HTML/CSS web page and converting to PDF right at the end.
As a result of using the Mill build tool, rendering of the book was automatically incremental and parallel:
If I compiled the book PDF from scratch, different chapters would render in parallel as much as possible before being combined into the final PDF, taking about a minute in total
If I then made a change in a single chapter, only that chapter would re-render, which takes just a few seconds
This kept the feedback loop fast, even when I wanted to generate print-ready PDFs for myself or my reviewers to review.
In addition to generating nice PDFs, there were a bunch of auxiliary considerations:
I needed 5-chapter previews for people to download off of the book's website https://www.handsonscala.com/
I needed both print-ready PDF as well as "compact" thin-margin PDFs, since when reading on small screens the margins on the print-ready PDFs make the content smaller and harder to read
I needed a pure-HTML 5-chapter preview for people to read online on the book's website https://www.handsonscala.com/table-of-contents.html
I needed epub and kindle/mobi versions of the e-book
The actual "print-ready" PDF needs several tweaks that the normal PDF doesn't, e.g. wider gutters on the inside-margin of each page to ensure the book looks good when open
Table-of-contents page numbers on the web should be blue links, but on the print edition they should be black text.
The 5-chapter previews should have modified table of contents pages to indicate which chapters are not included
While the "EPub" format is just zipped HTML/CSS, many CSS rules that work well in the browser and in Puppeteer do not work in most epub readers, and alternatives or compromises must be found
Kindles reading the .mobi format, which we convert from the EPub version, have their own set of quirks about what they like to render and what they don't
The kindlegen program that is used to convert from EPub to .mobi has a tendency to segfault when it sees HTML/CSS it doesn't like, rather than giving a proper error message.
Code snippets in the PDF and epub version should hyperlink to the online versions on the handsonscala/handsonscala Github repo
The print version should use a different color palette than the digital version because the printer colors are less saturated than most modern screens.
All these tweaks were easily added on to the Mill build pipeline I was using to render the book. There's an absurd amount of details into making things work nicely, but I did it.
The Mill build tool also made it easy to maintain my code examples: all code examples from the book, as well as solutions to the exercises, are from a test suite in the linked repository above. This makes it easy to run a test suite to verify that the examples are functional, and ensure that the code I am giving people actually works.
All code examples are self-contained, and each example has a test case that is run via a simple bash command. Any user who wants to try out an example on their machine can simply download the folder from the repo:
Run the bash command, and it should just work. I made sure to test all examples on Linux, MacOSX, and Windows (WSL2 Ubuntu) to ensure they can run on anyone's machine.
Every exercise solution, together with unit tests. Many of the code examples and exercise solutions build off each other, e.g. 13.3 Parallel Crawler builds off of 13.2 Crawler, and so I automatically generate a diff for you to visualize the difference. Every example can be downloaded and run with the bash snippet provided.
The exercises in the book were written with a mix of motivations:
All solutions are provided, which can serve as a cookbook if the reader wants to kickoff a new project and wants some example code to start.
Many of the exercises were written after the e-book was already published, but before the physical copy was printed. As they were added, those who purchased the e-book got updated copies.
The website https://www.handsonscala.com/ was also hand-written, generated as a static site using the same Mill build pipeline as the rest of the book.
I put a lot of effort into the website:
Making it look good full-screen on a computer, making it look good half-screen on a computer, making it look good on a mobile phone
The chapter listing is interactive, so people can click around and see the cover page of each chapter and read more about what it's about.
Making the online web version of the 5-chapter preview also responsive and pleasant to read no matter the screen size
The "Chapter Graph", showing the overall structure of the book and how the various chapters build upon each other:
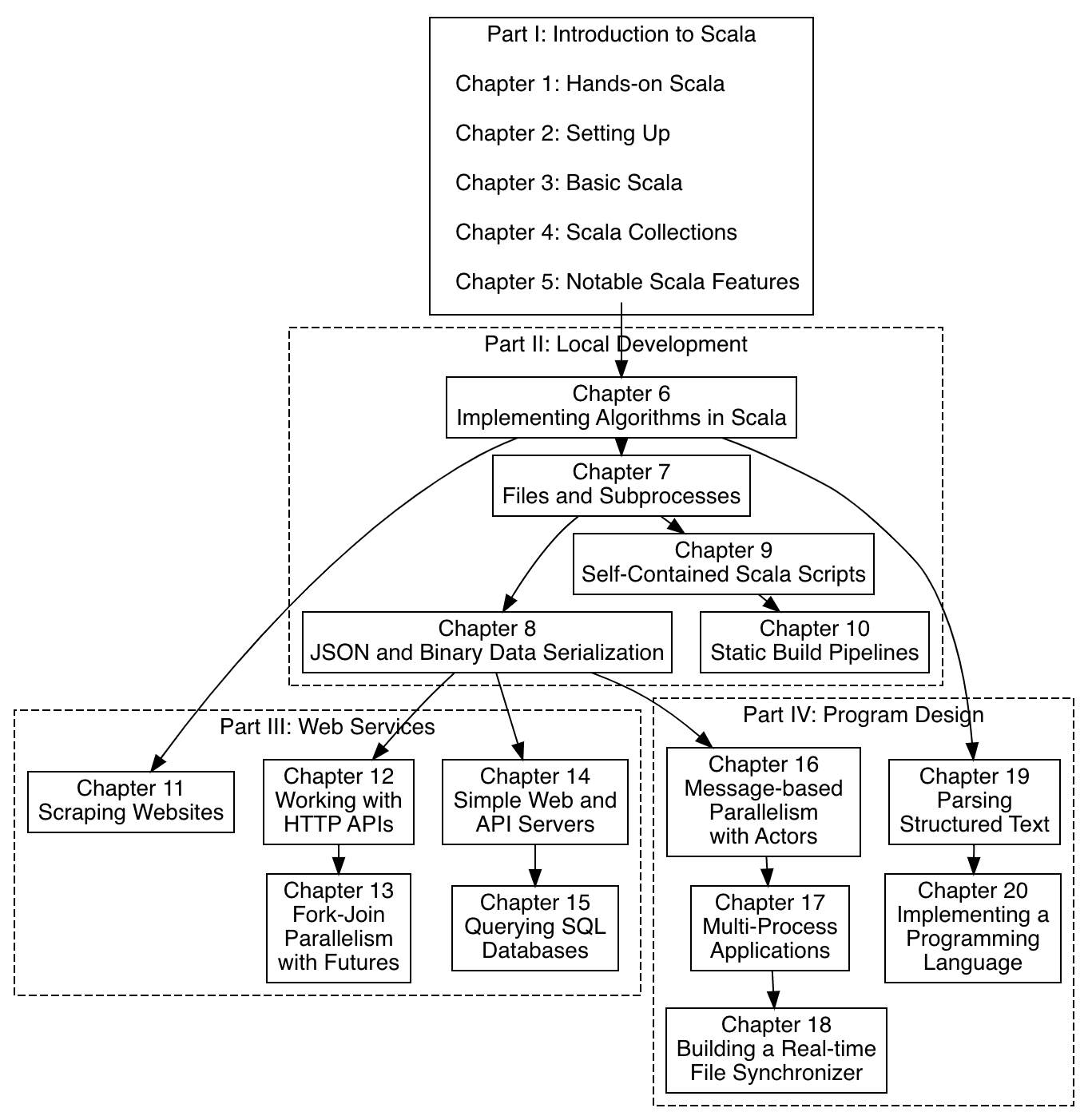
Lastly, I set up a simple discussion forum for the book, in the Github issues page:
Each chapter gets one issue, and it's a place for people to post questions, answers, show off their solutions to exercises, and so on. Not every chapter has a lively discussion, but overall it's definitely been successful at giving people a place to talk about the book.
The e-book of Hands-on Scala Programming was launched in June 2020, one year after the work started, just as planned. The physical copy took a bit more time to arrange, and ended up on Amazon in September 2020. Most of that time was spent ordering draft copies, waiting for them to arrive, and tweaking things until they looked just right in print.
On the first day of launch, Hands-on Scala Programming sold 91 copies, and on the second day 72 copies. While it quickly dropped off from there, even a year and a half later I'm still getting a small trickle of copies sold. The fact that I self-published means I could keep a lot more of the sales: 95% for e-book and ~30% for print, v.s. a tiny fraction of that (typically 5-10%) if I had gone through a traditional publisher. It's made a decent amount of money overall.
Finally, I had a nice cover image made by someone on Fiverr, put the PDFs up for sale on Gumroad, and put the print-copy up for sale by uploading the print-ready PDFs to IngramSpark. IngramSpark allows you to order preview copies before the book is officially listed, and it took me about 10 iterations of ordering a preview copy and fixing bugs before I hit "publish" and listed the book on Amazon and elsewhere.
Books sold on Gumroad let me keep 95% of the retail price, while physical books sold on Amazon let me keep about ~30%: 30% goes to Amazon, ~40% goes to printing costs. I chose to print in color, which costs twice as much as black-and-white: to me the improved reader experience of reading the book in color is worth more than the potential savings. I put a lot of effort into making this book look pretty: colored syntax highlighing, colored diffs, colored diagrams, and I'm not going to throw that all away to save a few bucks.
In theory, I could have saved on printing costs by arranging my own bulk printer and selling on Amazon as a seller, or using Fulfillment by Amazon, or by some other arrangement. In practice, I was happy to pay a few more bucks to not have to get into the logistics business; my expertise is writing code, not optimizing supply chains.
I made sure to reach out to all my contacts to popularize my book as much as possible.
From my decade of open-source work, I had contacts in many Scala using companies and many Scala meetup. I reached out to all of my friends and asked for a favor to send out news of my book's launch to their internal mailing lists.
I managed to go viral on Reddit and Hacker news (twice 1 2!).
I announced it on Twitter where I had an existing following around my open source projects
I added a link to the book's website on the readme of every single open source project I maintain. Every library, every tool, now has something saying "hey if you like this, you might like this book by the same author"
I gathered the emails of interested parties on my blog's mailing list, and sent out several email blasts: first to announce availability, and later to announce discounts
In theory, if I wrote a good book, word of mouth would help it spread. In practice I did everything in my power to ensure a good launch and kickstart the process.
I did not do any paid marketing to promote my book. Mostly because I didn't know how to, and I was too lazy to learn. Perhaps I should have; while the launch turned out OK, perhaps it would have turned out even better with an extra marketing boost.
Writing a Hands-on Scala Programming was an enormous amount of work. Looking back at it, even just setting up the build pipeline was a huge effort, not to mention writing, editing, and managing multiple rounds of reviews with twenty external reviewers. The ecosystem that the book builds upon was also a lot of work, albeit spread over the last decade.
Despite the difficulty, I must say that writing the book went entirely as planned. I set out to take a year to write it, and that's how long it took. I set out to take about half that time to write and half that time to edit, and I did. I selected a few dozen reviewers expected that a bunch would drop out, and they did. I set out to have a moderately successful launch and reception, and that's what I got. Nothing more, nothing less.
In the end, I had to write this book. I was the one pushing for the Scala language to be used in this particular way. I was the one who built all the libraries and ecosystem that makes it possible. I was the one with the vision of what Scala could be. I had to write it.
Scala is a niche topic, so Hands-on Scala Programming is never going to sell huge numbers the same way books on more popular topics do. Nevertheless, this book is more than just a book: it is the capstone of 10 years of open source development, it is my crystallized thoughts about how the Scala language should be used, it is a demonstration of how a modern programming language should be able to solve difficult challenges in simple and elegant ways.
About the Author: Haoyi is a software engineer, and the author of many open-source Scala tools such as the Ammonite REPL and the Mill Build Tool. If you enjoyed the contents on this blog, you may also enjoy Haoyi's book Hands-on Scala Programming