
Table of Contents
Today marks my 4th year anniversary at my current employer, Databricks. It's been a good run, and this is a great chance to reflect on the journey so far. This post is as much for me to organize my own thoughts as it is for anyone else to read.
This is a bit of change from the normal programming content on this blog, but given that my job is a programming job, writing lots of Scala, I suppose it still fits!

About the Author: Haoyi is a software engineer, and the author of many open-source Scala tools such as the Ammonite REPL and the Mill Build Tool. If you enjoyed the contents on this blog, you may also enjoy Haoyi's book Hands-on Scala Programming
Four years ago, in 2017, I was on the job market looking for a job. At the time I had already left my previous employer, so I had copious free time to explore what I wanted to do. I knew I wanted a software engineering job, and not much else.
I must have talked to at least two dozen prospective employers of all sorts, and ended up doing about 15 full rounds of interviews with various folks in Singapore, San Francisco, and New York. These ranged from the smallest startups, to big established tech companies, to banks and other more traditional outfits.
I ended up with a number of job offers, and a number of rejections. The offers were from a smattering of companies big and small. The selection was as you would expect; the big B2B tech company, the big Ad-based tech company, the big consumer software company, the big tech conglomerate, the medium sized B2B startup, the medium sized B2C startup, the hedge fund, etc.
I won't go into the details of my job hunt, but suffice to say that it was entirely as expected: a mix of vanilla coding interviews, system design interviews, culture fit interviews. The culture varied widely between companies, from "literally everyone here is super happy" to "these interviewers clearly do not want to be working here". The offers were as expected, with a significant variation in total comp between them.
Databricks was not the company that I would have initially imagined I'd end up joining.
At the time a low profile startup in the B2B space, even my ex-colleagues at Dropbox just a few blocks down Spear/Brannan street in San Francisco has no idea what a Databricks was. The offer was a good one, but not the highest one I got (at least as far as the equity of these private companies can be compared!).
It was also not the company I had the most personal ties to in 2017; in fact, one of my friends had worked at Databricks before and hated it! My only other connection to the company was a single meetup three years back (2014) that one of the founders had invited me to. But a job search is a numbers game, and as someone who wasn't at the time employed I had all the time in the world talk to anyone and everyone who would humor me.
By the end of my job search I was quite set on my decision to join them over others. My motivations for joining Databricks breaks down into a few main categories:
Probably one of the strongest motivations for joining Databricks was the fundamentals of the field that they were in. Databricks at the time was a Spark/big-data company rebranding into an AI company.
Even ignoring AI, it seemed "big data" was forever going to be a thing. Big companies exist, with more data than you can fit on a single machine, and wrangling big data using old tools like Hadoop and Hive was not a great experience. People were going to want to process that big data, even if just for basic analytics and summary statistics. For these purposes, Spark on Databricks was as good a tool as any.
Circling back to AI, there were a lot of AI companies going on in 2017. But there was a certain synergy between big data and AI that I thought Databricks was particularly well positioned to exploit.
In the paper Hidden Technical Debt in Machine Learning Systems, Google argues that in any AI system, the vast majority is not the clever algorithms, but rather the "plumbing" that surrounds those algorithms. Data collection, cleaning, verification, infrastructure, all need to be in place in order to support whatever machine learning you want to do.
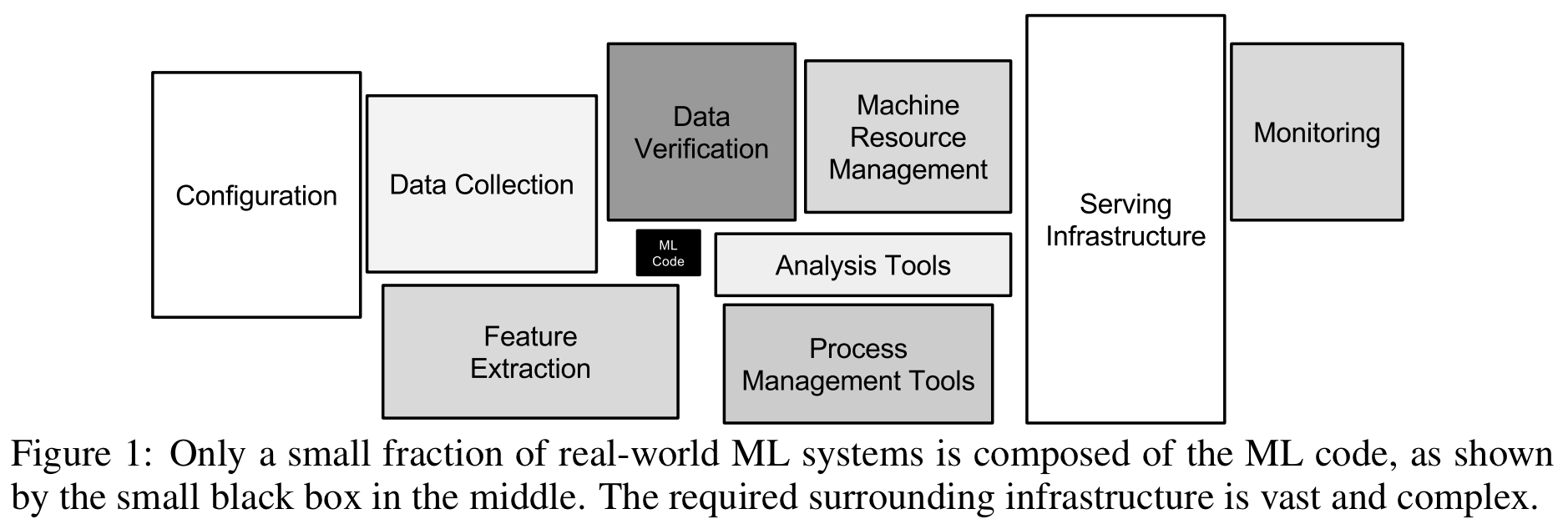
There were other similar publications in the early-mid 2010s, and I recall one by Facebook (that I can't find now...) which came to a different but related conclusion: "In AI/ML, more data beats smarter algorithms". It was quite clear to me that the reality of the field was that big data processing infrastructure was already a core part of AI/ML for the big savvy tech companies. It was only a matter of time before it became part of AI/ML for everyone else.
Fundamentally, it seemed at the time that many of the AI-related companies were fighting for the small square in the middle, while Databricks was relatively uncontested aiming for the bigger picture. Regardless of what kind of AI or ML someone wants to do, they will probably need some kind of big data processing pipeline to go along with it, and that intersection was where Databricks was primed to be.
The people at Databricks seemed nice, smart, and I could get along with them. This may seem like a pretty low baseline, but I definitely talked to many companies where the interviewers didn't seem nice, or didn't seem smart, or were both nice and smart but I for some reason didn't click with.
Below is an excerpt from my job search notes at the time, from one of the companies that I didn't end up joining:
At Databricks I felt pretty good about the people I met. Not perfect, but pretty good. And that's about as good as it got out of the 15 different companies I did a full interview loop with.
Databricks at the time was fully focused around Apache Spark. Spark was an amazing piece of tech.
It's not to say that Spark didn't have issues; like any old, sprawling, widely used system, it has definitely accreted its share of cruft. But the amount of stuff that had gone into Spark, even at the time, was very impressive.
From code-generating query compiler, to the efficient in-memory data formats, to the distributed map-reduce engine, to the crazy hoops PySpark jumps through to expose the Spark program running on the JVM to data scientists running Python, there is a lot of stuff in Spark that is both deep and valuable. While some startups could easily have their product cloned by a big tech company with unlimited budget and headcount, the things that make Spark Spark wouldn't be so easy to replicate.
Perhaps even more interesting than the tech itself, was the tech strategy: Apache Spark was constantly cannibalizing itself in order to find better and wider product market fits. From distributed Scala collections, to PySpark to support data scientists, to Spark-SQL to try and support data analysts, and so on.
While the constant churn has definitely left a mark on the codebase, I took it as a good sign that the authors were relentless in moving heaven and earth in pursuit of their customers. This is something that I had seen many startups fail to do, as they become inwardly fixated on their existing product and tech, to their detriment and eventual doom. It seemed likely Spark and Databricks would avoid that fate.
The last reason I joined Databricks, as I tell people, was because "things were on fire".
In many other companies, including those on my final shortlist that I was considering joining, things felt... good. Business doing well, engineers all happy, systems humming along with the necessary experts keeping them going. Whether in a big startup that already won their space, or in a larger company with infinite funding for a new project, things tended to be comfortable. Below is an excerpt from my job search notes, from one of the companies I didn't end up joining:
2017 Databricks was... not comfortable.
2017 Databricks had a ton of fires. Internal systems that were just broken, tons of missing processes, huge gaps of missing expertise as the business grew fast and engineering struggled to keep the pace. Code quality was poor, system architecture was nonsensical, infrastructure constantly falling down. It was clear even after a casual conversation that everyone was in way over their heads. I found out soon after joining that the team I had joined had just imploded from 3-4 people down a single individual as the others quit.
Some people may turn up their nose when they see such an outfit, but instead I saw opportunity. This was a place where I could come in and immediately find things to do that would make things concretely better.
Databricks also had a fire in the belly: engineering was having trouble keeping up because the business was growing, along with its demands. This was a business with a burning desire to re-invent itself, growing and evolving rapidly. Like Spark itself, Databricks was not resting on its laurels, but aggressively going after new markets and use cases. I remember one thought I had: if the business was doing well despite all these glaring engineering issues, how well could the business do if I helped fix them?
The best places to grow are not the places where everything is peachy. It's the places where there's pressure on you to perform, and there is space for your performance to really make an impact. Most of the places I had offers from, I could have had a comfortable job and made plenty of money just going along for the ride. At Databricks in 2017, it definitely felt like the future, or even having a future, was entirely up to us. No fate but what we make.
I've been largely on Databricks DevTools for the past four years. We do the work you cannot do without, keeping engineering and product moving forward relentlessly: testing infrastructure, dev infrastructure, build tooling, etc.
While many of these things can easily be taken for granted, they can just as easily bring the entire development process to a screeching halt if not done well. Any mature engineering team needs this stuff, so either they get it in order, or they die. And a lot of the work is very challenging, so "get it in order" is harder than you may think!
The work I've done on DevTools is split between fun greenfield projects and more iterative incremental improvements to older systems and codebases.
Some interesting greenfield projects I have built include:
Sjsonnet, a from-scratch implementation of the Google Jsonnet configuration compiler, except orders of magnitude faster (at the time, they may have caught up a bit by now). I built the IntelliJ plugin for the language as well.
A bespoke CI system that manages an elastic cluster of hundreds of cloud VMs, tends of thousands of CPU cores, to run pre-merge and post-merge validation on all our engineers' pull requests.
Devbox, a seamless remote dev environment: write code on your laptop, run shell commands on your code on a fast cloud VM co-located with all your cloud infrastructure (docker registries, build caches, kubernetes clusters, etc.)
A tracing garbage collector for multi-cloud infrastructure on AWS, Azure, Kubernetes, etc.. Doing a liveness analysis on the ownership graph of our cloud deployments, to detect leaked resources that all other techniques had failed to clean up.
Some interesting "incremental" projects include:
Speeding up Scala compilation via a huge bag of tricks, ranging from cloud infrastructure to language-level tooling
Massively Speeding up PR testing and validation, turning a multi-day affair full of flakiness and frustration to one that can be done in less than an hour
Stabilizing our cloud testing environments and scaling them out by orders of magnitude to support all our manual- and integrating-testing users and use cases.
Apart from these projects, there's also just the "work": small things that may not fall under any umbrella, but which need to be done.
One of the first things I did upon joining was speeding up a core development loop from 8 minutes to 30 seconds. No more waiting 8 minutes to see the effects of a println made a lot of people very happy!
Another time I noticed that someone's dev cycle was taking no less than 45 minutes, going through a bunch of jenkins jobs and all sorts of other crazy things. I managed to bring that time down to about 2 minutes with a short Python script. Writing that script took 30 minutes; I started and finished writing it before the person I was helping had done a single iteration through their dev cycle !
These are just a sampling of the kind of work we do on Databricks DevTools. There's really been no shortage of difficult projects, interesting projects, and projects that are both difficult and interesting. It would be hard to imagine any other place I could have worked that would have given me such a wide range of projects work on, from compilers to distributed systems to web applications to cloud infrastructure, from greenfield ventures to the most brown of the brownfield maintenance jobs. And all this not because I was purposely going for variety, but because these were the things to do to make the biggest impact on the team mission and company bottom line.
One interesting thing about our work on Databricks DevTools is that the problems are hard. The scale is large, the systems are complex, the tech is absurdly broad and deep. There's tons to do and no upper bound in the amount someone can contribute. Even if you come in as a deep expert in a dozen different fields, we have challenges that will make you sweat, with a corresponding amount of satisfaction if you can overcome them.
Apart from the technical work, there's also a lot of interesting non-technical work going on: organizing team processes and protocols, knowledge sharing, mentorship, and trying to train people up to take more heavy responsibilities. I helped build a squad in the EU timezone, and helped mentor countless people to make them productive contributing members of the team at Databricks.
Databricks in 2021 is not the same company as Databricks in 2017.
It's much bigger, and much more established. Databricks with a 50+ person engineering team isn't the same as Databricks with a 500+ person engineering team, and there's no way around it. In 2021, Databricks is a big name, and software folks working a few blocks down the road now know what Databricks is.
However, that doesn't mean the fires have gone out. On the contrary, Databricks is still evolving the business rapidly, and engineering is still racing to keep up. There are a lot of ambitious changes to the business happening in short timescales. There are still a lot of problems that need to be solved, whether new problems as the business moves forward or old problems that have re-surfaced as usage of our systems reach unprecedented scales.
The other fundamentals that caused me to choose databricks over others haven't changed. In 2021, "Big Data" still isn't going away, and any kind of AI/ML work often needs to be supported by big data infrastructure. In 2021 Spark is still pretty cool, and despite showing its age is still aggressively evolving to meet new needs and use cases. The people at Databricks in 2021 seem smart and nice and easy to get along with, both the old folks, the new folks, and the folks who left and came back!
I can't predict the future, but I joined Databricks 25th September 2017, and four years later on 25th September 2021 I'm still here.
(This isn't a corporate blog, so I won't end with a link to the Databricks careers page)
About the Author: Haoyi is a software engineer, and the author of many open-source Scala tools such as the Ammonite REPL and the Mill Build Tool. If you enjoyed the contents on this blog, you may also enjoy Haoyi's book Hands-on Scala Programming