Planning Bus Trips with Python & Singapore's Smart Nation APIs
The Singapore Smart Nation initiative is a government push to try and improve the efficiency of Singapore, as a country, using technology. Among other projects, there has been a push to make real-time data openly available so that everyone, from individuals to corporations, can use it creatively to make solutions to day-to-day municipal problems.
This post will explore one such dataset: the LTA Data Mall, by Singapore's Land Transport Authority. This dataset provides both offline geographical data on roads & public transport, as well as real-time data on things like bus arrivals and taxis. Using this dataset, the Python programming language, and basic programming and data-science techniques, we will build a trip planner to find the shortest bus commute from A to B, but powered by real data and bounded by real-world limitations.
From registering an API key, fetching data from an endpoint, sanitizing and understanding the data, implementing algorithms like a Breadth First Search or Dijkstra's Algorithm, refining the search, and finally evaluating its ability to plan useful and correct bus trips. You'll get a full tour of the process involved in making good use of public datasets!

About the Author: Haoyi is a software engineer, and the author of many open-source Scala tools such as the Ammonite REPL and the Mill Build Tool. If you enjoyed the contents on this blog, you may also enjoy Haoyi's book Hands-on Scala Programming
This post will walk you through how to make a bus-trip-planner using the data published on the LTA Data Mall. We'll start off from first principles - browsing and registering for an API key on someone's website - and advance through downloading the data, working with in the IPython shell, building it into a proper script and gradually building more and more on top of what we have, with better algorithms and modeling, until we have a useful bus-trip-planner written in <150 lines of Python!
There are two reasons this post is interesting: first, it demonstrates how easy it is to get started working with "Open Data" and building something useful. Second, it demonstrates how basic algorithms, the sort someone learns in their undergraduate computer science course and have promptly forgotten upon graduation, can actually be really useful if applied to a real-world data-set.
APIs change, systems come and go, and the Singapore Smart Nation is a work in progress. This post will be based on what's available at-time-of-writing, and will definitely become outdated over time. Hopefully, though, the techniques demonstrated and lessons learned will remain interesting long after that!
So let's begin...
Exploration
The first step in any project should be a literature review: what is available? What things are out there? What can you use? What looks promising and what looks un-interesting? Rather than diving straight into a project, this survey can help give you ideas of what's possible and what's infeasible, and an hour or two spent here can save days or weeks later when you're deep in the weeds.
Exploring the Smart Nation
Many datasets are available on the data.gov.sg website or on the website of various organizations: the National Library Board Dataset, the National Environmental Agency Dataset, the OneMap API, or the LTA Data Mall by the Land Transport Authority. These datasets range from static CSVs updated once a year with a single new row, e.g. the data on Government Headcounts:
| financial_year |
actual_revised_estimated |
ministry |
count |
| 1997 |
Actual |
Civil List |
44 |
| 1998 |
Actual |
Civil List |
47 |
| 1999 |
Actual |
Civil List |
45 |
| 2000 |
Actual |
Civil List |
45 |
| 2001 |
Actual |
Civil List |
50 |
| 2002 |
Actual |
Civil List |
47 |
| ... |
... |
... |
... |
To daily XML feeds, e.g. the Current Weather Forecast:
<title>Singapore - Nowcast and Forecast</title>
<source>Meteorological Services Singapore</source>
<main>
<title>24 Hour Forecast</title>
<forecastIssue date="28-03-2016" time="11:33 AM" />
<validTime>12 PM 28 Mar - 12 PM 29 Mar</validTime>
<temperature high="34" low="25" unit="Degrees Celsius" />
<relativeHumidity high="90" low="60" unit="Percentage" />
<wind direction="NE" speed="10 - 30" />
<wxmain>PS</wxmain>
<forecast>Occasionally windy. Passing showers mainly over northern and western Singapore in the late afternoon.</forecast>
<pastweather>Nil</pastweather>
</main>
...
To real-time, minute-by-minute JSON about bus arrival times from every bus stop in the country, from the LTA Data Mall:
{
"BusStopID": "83139",
"Services": [
{
"ServiceNo": "15",
"Status": "In Operation",
"Operator": "SBST",
"OriginatingID": "77009",
"TerminatingID": "77131",
"NextBus": {
"EstimatedArrival": "2015-03-03T07:20:24+08:00",
"Latitude": "1.421179",
"Longitude": "103.831477",
"VisitNumber": "1",
"Load": "Standing Available",
"Feature": "WAB"
}
},
...
]
}
The exact format of the data is immaterial: these are all standard formats, and as a developer any programming environment would have tools built-in or easily-available for dealing with them. With a bit of googling, extracting the data you want should be a matter of minutes, so what really matters is what data is available. Apart from these, there is a long list of APIs provided by other, non-government, organizations: the gothere.sg API, the OpenWeatherMap API, and many more too numerous to list.
As you can imagine, not all data is available in all formats which you could possibly want it in. Furthermore, not all data-sets are of equal interest to someone who's approaching it from the point of view as a developer: if your dataset gets updated once a year with a handful of new row of 4 columns each, as the Government Headcounts dataset does, it's perfectly feasible to deal with it manually once a year. Even data updated every day can be dealt with manually, without any automation, even if it ends up being somewhat tedious.
As a developer, what is most interesting is the high-frequency, high-volume, possibly real-time data that is totally impractical to deal with manually. Not only is that more intesting from a technical perspective, that is where a developer is able to contribute the most value: by creating something or providing a service nobody else can!
For the rest of this post, I'll focus on making use of the Land Transport Authority's LTA Data Mall datasets.
Exploring the LTA Data Mall
When you first visit the LTA Data Mall, you are greeted with a plain website with a bunch of links:
It's not the prettiest most design-driven website, but it'll do for now. Most interesting to us is what's available:
STATIC DATA
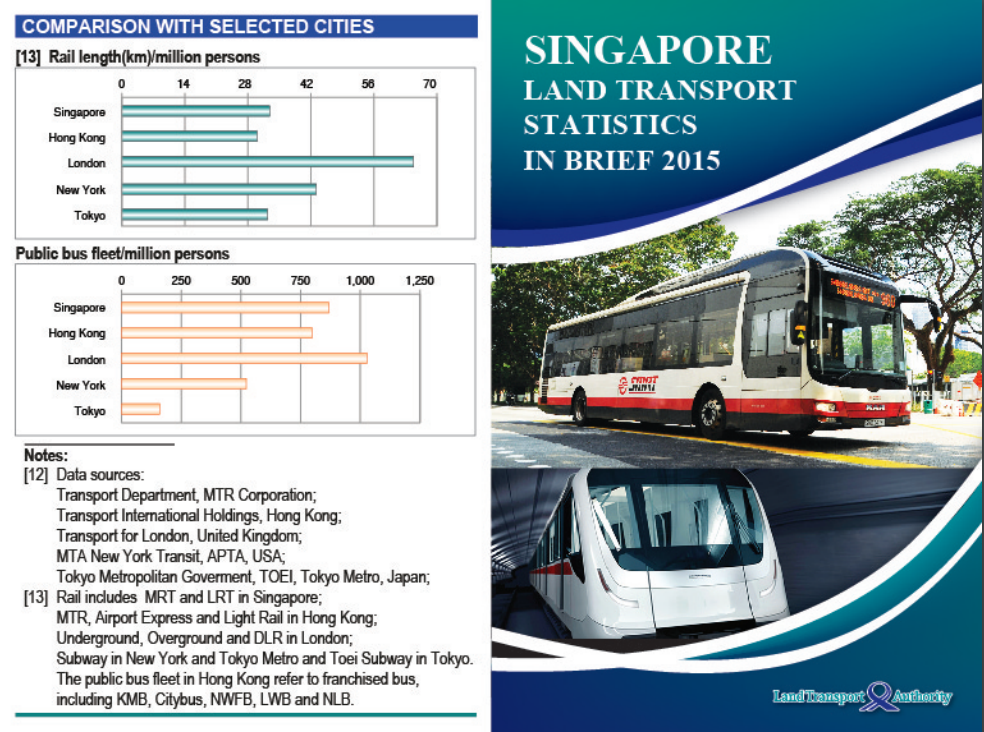
PDFs, XLS Excel spreadsheets, and SHP Shapefiles that presumably are updated infrequently. The PDF files look like slide decks and are geared towards impressing your boss. Many of them link to the same Statistics in Brief deck:
There are other less-showy PDFs, but they are similarly low-frequency, low-volume data that can be dealt with manually, and thus isn't interesting to a developer.
The CSV files are of borderline interest. While infrequently updated, they are almost of sufficient volume that it's interesting to deal with them programmatically. For example, the Park & Ride Location is just 41 rows and fits nearly on one page:
SR_NUM,LOC_TXT,CARPARK_CD,OWNR_TXT,REGION_TXT,LONGTD_TXT,LATTD_TXT
"1","Blk 31A Eunos Crescent","ECM","HDB","East","103.90161000000000","1.32000000000000"
"2","Blk 11A Pine Close","KM3","HDB","East","103.88296000000000","1.30852000000000"
"3","Blk 531/536 Pasir Ris Drive 1","PR3","RCS","East","103.95114000000000","1.37138100000000"
"4","Blk 114A Lorong 3 Geylang","SDM","HDB","East","103.87444100000000","1.31242800000000"
"5","Blk 248 Simei Street 3","SIM4","RCS","East","103.95354100000000","1.34359400000000"
...
"37","Blk 257A Boon Lay Drive","BL15","HDB","West","103.70756500000000","1.34598700000000"
"38","Blk 484-491 Jurong West Avenue 1","J45","HDB","West","103.72680000000000","1.34910800000000"
"39","Blk 8A Empress Road","FR3M","HDB","West","103.80618000000000","1.31671000000000"
"40","Blk 16A Ghim Moh Road","GM6B","HDB","West","103.78758000000000","1.30968000000000"
"41","Blk 78A Telok Blangah Street 32","TBM3","HDB","West ","103.80900000000000","1.27329000000000"
While others like the Premium Bus Service file has a 1-2 thousand rows and many columns in each one. Overall, these are still of the size that you can load them up in an excel spreadsheet and have any corporate excel wizard deal with them semi-manually. Thus, they're probably not really of interest to a developer.
Lastly, you have the SHP Shapefiles. Those are of potential interest, since they provide blobs of geospatial data that lets you find e.g. every single road, traffic light or train-station on the map. This could be potentially interesting to a developer if you wanted to write path-finding software for cars, or other things involving maps or navigation.
REAL-TIME / DYNAMIC DATA
While much of the Static Data isn't that interesting from a developer's point of view, the real-time/dynamic data is a totally different story. These are large data-sets that are updated often, some every 1-2 minutes, and definitely need a developer to deal with and turn into a usable or interesting service.
The description for the real-time/dynamic data includes the Data Mall API User Guide, which is a downloadable PDF file containing all the instructions, examples and specifications you'd expect to find on the website of an API provider. It's a bit unusual to have it as a downloadable PDF instead of just part of the website, but it'll do for now.
It appears there's example data below that you can download in an XML format without having to write any code to deal with, but if we're going to be dealing with dynamic, "real-time" data we're going to have to figure out how to make the computer do the work of fetching and processing the data eventually, so might as well do that sooner rather than later.
The Data Mall API User Guide includes 15 different API endpoints that line up with the XML examples we saw earlier. Here is a short description for the ones which I thought were interesting:
-
Bus Arrival: given a stop, tells you when the next three buses are coming for every service that stops at that bus stop, and other misc data (e.g. the lat/long for each bus on the map)
-
Bus Services: all bus services that are currently in existence, and data about who runs them, where they start/end, and their frequency, without which stops they service
-
Bus Routes: every bus stops every service stops at, in what order.
-
Bus Stops: all bus stops in the country, with their name (e.g. "Hotel Grand Pacific"), code (e.g. 01012) and lat/long on the map.
-
Taxi Availability: every taxi that is currently available (i.e. showing it's green light) and their lat/long on the map
-
Carpark Availability: a listing of popular carparks, their lat/long on the map, and how many lots they have available right now.
-
ERP Rates: all ERP gantries on the island, with their rates for each time period they're active
-
Estimated Travel Times: roughly how long it takes to drive between two roads on the island.
-
Faulty Traffic Lights
-
Road Openings
- Road Works
- Traffic Images
- Traffic Incidents: the lat/long for any current incidents that may result in traffic slowdowns: roadworks, accidents, etc.
- Traffic Speed Bands: how fast traffic is on various roads around the island
- VMS/EMAS
Some of these, such as Road Opening*, Road Works, and Traffic Images, are pretty self-explanatory and give you exactly what you'd imagine. Others, like Faulty Traffic Lights, are pretty obscure and not that interesting.
Not all of these are as "real time" as I had originally thought: for example, the Bus Services or Bus Routes APIs probably won't change all that often, and Bus Stops take time to construct. On the other hand, APIs like Bus Arrival, Taxi Availability or Traffic Speed Bands are most definitely real-time, changing minute-by-minute, and could probably be used programmatically to make interesting services that are impossible to do by hand.
Getting Started
Before we get started writing code, we have some non-technical things to sort out: we need to figure out what we want to do, and we need to register an account with the LTA Data Mall telling them what we are going to do so they can give us access to the API.
Picking a Project
We've by this point gone through a tour of some of the APIs available as part of the Singapore Smart Nation initiative; from a high-level overview across different organizations providing different sorts of data sets, zooming in to just those available within the LTA Data Mall, and zooming in further to just the "real-time" APIs as the most promising. It's time to figure out something to do with these "promising" APIs, so we can get our hands dirty and see what it's really like trying to work with the output of this Singapore Smart Nation thingamajig.
Given these "promising" APIs, let's pick an arbitrary goal: to write a trip planner to find the shortest bus trip between two points on the island. This is something that Google Maps, GoThere.sg or the MyTransport.SG journey planner already provides, and there's no way we'll "beat" one of those established services right off the bat. Nevertheless, it'll still be interesting to see how far we can get! This should give us a good chance to explore the various APIs and datasets that are available, and at the end of the day have something useful and relateable to show for it.
Registering an Account
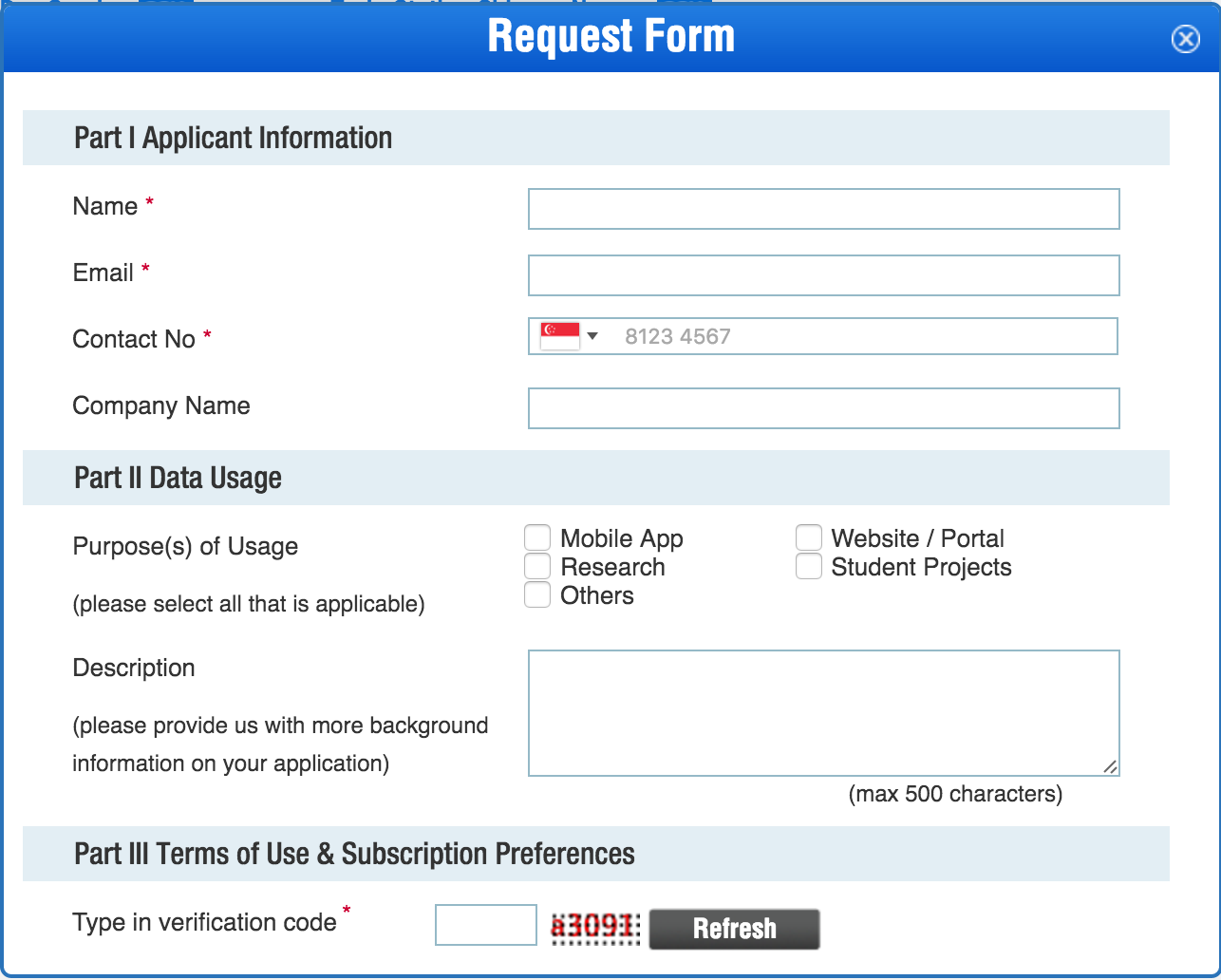
The first thing you need to do to get started with the LTA Data Mall API is to register and account and get an API key. This can be done via the Request for API Access link on their home page:
It's a slightly awkward web-form, and it's not clear how you submit it until you realize the form is scrollable and the submit button is below:
Slightly awkward, but no big deal. Overall, this is similar to how getting access to most other third-party APIs works, e.g. if you want API access to integrate with Facebook or Dropbox. In all cases, they want to know
- Who you are
- What you're doing
- How they can contact you if there's a problem.
As far as I can tell the registration goes through automatically, and you'll get an email confirmation:
Dear Li Haoyi,
Thank you for your interest in LTA’s DataMall.
The following API Account Key grants you access to all dynamic / real-time datasets in DataMall. For instructions on how to access the APIs and make use of the datasets, you may refer to the API User Guide here.
API Account Key: <--Your API key-->
Please note that this API Account Key is uniquely assigned to you and is not to be shared with anyone else. You are to observe the terms and conditions of use as acknowledged in your application, and refrain from hyperlinking your products and services directly to DataMall. Lastly, please do not make API calls excessively as DataMall is a shared resource. Your usage will be monitored.
Should you have any further queries, you may contact us at DataMall@lta.gov.sg.
Cheers, LTA DataMall Team
After that, you have to use your account key to get a UniqueUserID before you can start making requests to the API. As described in the Data Mall API User Guide:
DATAMALL ACCESS CREDENTIALS Upon successful registration via MyTransport.SG Portal, you will be issued an API Account Key. Note that this Account Key is uniquely assigned to you and is not to be shared with anyone else.
With the Account Key, you will need to generate your Unique User ID via DataMall’s Authentication Tool. These two pieces of info form your API authentication credentials that are required when you make your API calls. Steps to obtaining your API authentication credentials:
- Go to DataMall’s Authentication Tool - http://datamall.mytransport.sg/tool.aspx
- Enter your Account Key.
- Click on the button Generate GUID
- Your Unique User ID appears. You’re good to go!
It's not clear to me what this step serves in the registration process; I'd have guessed that it's meant to help you identify usage of the API from each end user of your app or service, rather than from your service as-a-whole, but the instructions don't ask you to generate a new key for each user. Anyway it doesn't really matter for now, let's just do what they say and if something's wrong we can figure it out later.
For this section of the post, I haven't shown the keys that get generated, since otherwise if many people start using the same keys the LTA can't figure out who's using the API to do what. If you want to follow along, feel free to register your own email to get your own Account Key or Unique User ID to use this API. It shouldn't take more than a few minutes!
Hello API
Now that we're done with the literature review and the administrative overhead, let's start writing code. I'm going to use
These should work on any laptop or desktop, whether running Windows, Mac OS-X or Linux. If you don't have them already, take the time to install them before coming back here. You'll know you've installed things correctly when you can type ipython to bring up the IPython shell, and then import requests and requests.get("https://www.google.com") to make a request to Google to make sure everything works:
haoyi-mbp:test haoyi$ ipython
Python 2.7.10 (default, Aug 22 2015, 20:33:39)
Type "copyright", "credits" or "license" for more information.
IPython 2.3.1 -- An enhanced Interactive Python.
? -> Introduction and overview of IPython's features.
%quickref -> Quick reference.
help -> Python's own help system.
object? -> Details about 'object', use 'object??' for extra details.
In [1]: import requests
In [2]: requests.get("https://www.google.com")
Out[2]: <Response [200]>
If the last command prints <Response [200]> as show here, you're ready to go. Let's get started with the API!
To use the API, we need to make a HTTP request to some URL provided by the LTA. Some computer listening at that URL will then take our request and provide the data we asked for.
The example on the 7th page of the Data Mall API User Guide tells us we need to pass in headers to our HTTP request, such as:
headers = {
'AccountKey': '6HsAmP1e0R/EkEYWOcjKg==',
'UniqueUserID': '8ee245d6-a53b-4an8-bdxe-18027af5e4c5',
'accept': 'application/json'
}
Where AccountKey and UniqueUserID are the things we got earlier.
- Note: if you are following along, make sure you register your own AccountKey and UniqueUserId and substitute them in! The ones shown are examples and will not work if you try to use them.
Let's try using that, together with Requests to make a HTTP request asking for the current bus stops, using the URL listed on the Bus Stops section of the user guide on page 17 of the Data Mall API User Guide:
In [1]: import requests
In [2]: headers = {
...: 'AccountKey': 'rmgDEFTiRRfcNeD8GbHqf8==',
...: 'UniqueUserID': '8ecabd56-08a2-e843-0a7a-9944dccf124a',
...: 'accept': 'application/json'
...: }
In [3]: requests.get("http://datamall2.mytransport.sg/ltaodataservice/BusStops", headers=headers)
Out[3]: <Response [200]>
This seems to have worked; the HTTP Status Code 200 is used to indicate a successful request. Using Requests, we can now get the response data, which we know to be in the JSON format:
In [4]: Out[3].json()
Out[4]:
{u'odata.metadata': u'http://datamall2.mytransport.sg/ltaodataservice/$metadata#BusStops',
u'value': [{u'BusStopCode': u'01012',
u'Description': u'Hotel Grand Pacific',
u'Latitude': 1.29684825487647,
u'Longitude': 103.85253591654006,
u'RoadName': u'Victoria St'},
{u'BusStopCode': u'01013',
u'Description': u"St. Joseph's Ch",
u'Latitude': 1.29770970610083,
u'Longitude': 103.8532247463225,
u'RoadName': u'Victoria St'},
{u'BusStopCode': u'01019',
u'Description': u'Bras Basah Cplx',
u'Latitude': 1.29698951191332,
u'Longitude': 103.85302201172507,
u'RoadName': u'Victoria St'},
...
And there you go, a list of bus stops in Singapore, along with interesting metadata about them: their lat/long on the map, the road they're on, their description, along with their unique BusStopCode. The returned JSON blob is a dictionary with two keys: 'odata.metadata', which contains something we probably don't care about, and 'value', which contains the list of bus stops that we do care about.
Paging
Let's see how many bus stops there are:
In [5]: len(Out[3].json()['value'])
Out[5]: 50
Fifty? There can't possibly be only 50 bus stops on the whole island. We could re-arrange the code we used to make the request, make another request to make sure we didn't do the wrong the first time, and sure enough it gives us the same result:
In [6]: bus_stop_url = "http://datamall2.mytransport.sg/ltaodataservice/BusStops"
In [7]: len(requests.get(bus_stop_url, headers=headers).json()['value'])
Out[7]: 50
If we search for 50 in the documentation pdf, we find:
API responses are limited to a max of 50 records of the dataset per call. To retrieve more records, you need to append the following parameter $skip=X’ to the API call (URL), withX` being a number of records to skip.
For example, if you want to retrieve the 51st to the 100th record for the Bus Stops dataset, the API call should be:
http://datamall.mytransport.sg/ltaodataservice.svc/BusStopCodeSet?$skip=50
To retrieve the 151st to 200th record, supply ?$skip=150, and so on. Remember, each URL call returns only a max of 50 records!
So that's why! we can only get 50 records at a time. Let's try skipping some entries using Requests to add the $skip parameter to it:
In [8]: requests.get(bus_stop_url, headers=headers, params={'$skip': 50}).json()['value']
Out[8]:
[{u'BusStopCode': u'02111',
u'Description': u'Esplanade Bridge',
u'Latitude': 1.29095592348389,
u'Longitude': 103.85453419435228,
u'RoadName': u'Esplanade Dr'},
{u'BusStopCode': u'02119',
u'Description': u'One Raffles Link',
u'Latitude': 1.29184407356581,
u'Longitude': 103.85534334305085,
u'RoadName': u'Nicoll Highway'},
{u'BusStopCode': u'02129',
u'Description': u'Aft Raffles Blvd',
u'Latitude': 0,
u'Longitude': 0,
u'RoadName': u'Republic Blvd'},
...
And sure enough, we get a different set of bus stops! Clearly we're being Paged. What if instead of the first 50 results or the second 50 results, we want all the results? That actually turns out to be pretty simple: write a loop that keeps requesting results until there are no more to request:
In [18]: results = []
In [19]: while True:
....: new_results = requests.get(
....: bus_stop_url,
....: headers=headers,
....: params={'$skip': len(results)}
....: ).json()['value']
....: if new_results == []:
....: break
....: else:
....: results += new_results
If we run this it takes maybe ten seconds, depending on how fast your internet is. When it's done we can see how many results there are:
In [20]: len(results)
Out[20]: 5260
Five thousand bus stops across the whole island! That's a more reasonable statistic.
Sanity Checking
With over five thousand results, that's twenty five thousand lines of output: definitely too much data for us to go over "by hand" to verify that it's all correct! Nevertheless, we can do some basic sanity checks to make sure things aren't totally busted. For example, we can verify that every entry in that huge list is a Python dictionary:
In [26]: set(map(type, results))
Out[26]: {dict}
This maps the type function over the list of items, converting it to a list of types, and then puts it into a set so that duplicates are removed. Thus we get the distinct types of all items in that list, and here we can see they're all dicts or Dictionaries.
We can also verify that none of the dictionaries have weird keys we don't expect:
In [27]: set(key for res in results for key in res.keys())
Out[27]: {u'BusStopCode', u'Description', u'Latitude', u'Longitude', u'RoadName'}
We can also query various attributes of these dictionaries; for example, what "RoadName"s would we find in those 5260 bus stops, and are they roads we're familiar with?
In [28]: set(result["RoadName"] for result in results)
Out[28]:
{u'AYE',
u'Adam Rd',
u'Admiralty Dr',
u'Admiralty Lane',
u'Admiralty Link',
u'Admiralty Rd',
u'Admiralty Rd East',
u'Admiralty Rd West',
u'Admiralty St',
u'Ah Hood Rd',
u'Airline Rd',
u'Airport Blvd',
...
If we spot check a few arbitrary roads, would the "Description"s of the bus stops on each road match up with what we expect? Here's all the bus stops along Orchard Road:
In [30]: [res["Description"] for res in results if res["RoadName"] == "Orchard Rd"]
Out[30]:
[u'YMCA',
u'Dhoby Ghaut Stn',
u'Macdonald Hse',
u'Orchard Plaza',
u"Concorde Hotel S'pore",
u'Opp Mandarin Orchard',
u'Midpoint Orchard',
u'Tang Plaza',
u'Lucky Plaza',
u'Delfi Orchard',
u'Royal Thai Embassy',
u'Non Stop']
And along Alexandra Road:
In [31]: [res["Description"] for res in results if res["RoadName"] == "Alexandra Rd"]
Out[31]:
[u'Gan Eng Seng Sec Sch',
u'Opp Gan Eng Seng Sec Sch',
u'Delta Sports Hall',
u'Opp Delta Sports Hall',
u'Opp Tanglin View',
u'Tanglin View',
u'SIS Bldg',
u'Opp SIS Bldg',
u'Aft SM Motors Ctr',
u'Opp SM Motors Ctr',
u'Alexandra Hosp',
u'Opp Queensway Shop Ctr',
u'Anchorpoint',
u'Bef IKEA Ind Bldg',
u'Opp Lea Hin Hardware Fty',
u'Lea Hin Hardware Fty',
u'NOL Bldg',
u'Opp NOL Bldg',
u'Alexandra Pt',
u'Opp Alexandra Pt',
u'SP Jain',
u'Opp SP Jain',
u'Non Stop']
Seems correct!
How about the locations of these bus stops? Are the latitudes and longitudes where we expect Singapore to be? The max seems to be roughly correct:
In [36]: max(res["Latitude"] for res in results)
Out[36]: 1.49390379286364
In [37]: max(res["Longitude"] for res in results)
Out[37]: 104.0046664051527
but the min seems odd:
In [38]: min(res["Latitude"] for res in results)
Out[38]: 0
In [39]: min(res["Longitude"] for res in results)
Out[39]: 0
How could it be 0? Singapore isn't on 0 latitude, and certainly isn't anywhere near 0 longitude! Perhaps 0 means "No Data" or "Missing Data" or something like that. How many of the bus stops have 0 for each?
In [41]: len([res for res in results if res["Latitude"] == 0])
Out[41]: 365
In [42]: len([res for res in results if res["Longitude"] == 0])
Out[42]: 365
Seems like a reasonable number have: 365 out of 5260 have invalid (0) lat and longs. We could even verify that they're all the same bus stops, which have both "Latitude" and "Longitude" for some reason set to 0:
In [43]: [res for res in results if res["Longitude"] == 0] == [res for res in results if res["Longitude"] == 0]
Out[43]: True
If we filter those out, we get a much more reasonable min for both "Latitude" and "Longitude":
In [47]: min(res["Latitude"] for res in results if res["Latitude"] != 0)
Out[47]: 1.25352193438281
In [48]: max(res["Latitude"] for res in results if res["Latitude"] != 0)
Out[48]: 1.49390379286364
In [49]: min(res["Longitude"] for res in results if res["Longitude"] != 0)
Out[49]: 103.62192147229634
In [50]: max(res["Longitude"] for res in results if res["Longitude"] != 0)
Out[50]: 104.0046664051527
Given that 1 Degree of Latitude is ~111.2km, and 1 degree of Longitude is going to be about the same since Singapore is near the equator, we can compute how "far" the various bus stops are spread across the surface of the earth North-South via the different in Latitude and East-West via the difference in Longitude:
In [51]: (1.49390379286364 - 1.25352193438281) * 111.2
Out[51]: 26.730462663068312
In [52]: (104.0046664051527 - 103.62192147229634) * 111.2
Out[52]: 42.56123653362821
Thus we have found that the bus stops in our list are spread roughly across 42.6 kilometers East-West and 26.7 kilometers North-South. This lines up with what we know of the Geography of Singapore: 50km East-West and 27km North-South. The bus stops with valid lat/longs seem to be spread roughly across the same area as Singapore itself, which is what we expect!
Something Works
At this point, we've got our first useful, complete, correct data set from the LTA Data Mall API. We've picked a project, signed up for API access, made some requests, worked around some weirdness due to paging and kinda-sorta validated our data to make sure it makes sense. Some of the bus stops are missing latitudes and longitudes, and there are probably other suble issues with the data we haven't noticed, but as a first pass it's looking pretty good and the ad-hoc spot checks we did all returned the results we expected.
This is, in many ways, the extensive "hello world" part of the project. We have not built anything of value, anything creative, and have not made anything that is "ours". What we have done is plumbed together Python, IPython, Requests and the LTA Data Mall API into something that we know works. The next step would be building on top of this into something interesting, creative and useful: our bus-trip-planner!
Building Out
We want to incorporate the working code we have into a larger application. In this case I want to build a stand-alone bus-trip-planner, but you can also imagine using the code in some existing project. Although we have something working, it's not something we can really build on top of or incorporate into a larger application
-
It currently lives in a IPython shell session, and if we close the session we lose everything and have to piece together what we did from the shell's history.
-
We have the ability to fetch all data from one DataMall API (/BusStops) using a while-loop, but we'll need to fetch any API, and many APIs! After all, we'll need to integrate the data about bus stops, bus routes, and bus services, and possibly other datasets, all into one coherent tool.
The first thing to do now is consolidate what code we already have. The code should live in a .py file, under version control. Any logic we will want to re-use, such as the while-loop for fetching more than 50 results, should be extracted into a re-usable function so it can be easily pointed at any endpoint. Only then will we be able to build on top of it, expand its functionality, and create our bus-trip-planner!
Consolidation
The first step in consolidation is converting the ad-hoc IPython session into a script we can run and re-run over and over easily, without needing to manually enter the same commands over and over. Here I put the relevant commands into a run.py file, which you can run via python run.py:
haoyi-mbp:test haoyi$ cat run.py
import requests
headers = {
'AccountKey': 'rmgDEFTiRRfcNeD8GbHqf8==',
'UniqueUserID': '8ecabd56-08a2-e843-0a7a-9944dccf124a',
'accept': 'application/json'
}
if __name__ == "__main__":
results = []
bus_stop_url = "http://datamall2.mytransport.sg/ltaodataservice/BusStops"
while True:
new_results = requests.get(
bus_stop_url,
headers=headers,
params={'$skip': len(results)}
).json()['value']
if new_results == []:
break
else:
results += new_results
print len(results)
haoyi-mbp:test haoyi$ python run.py
5260
This is valuable because it means you can tweak anything, re-run your program and be sure it'll return the same results as the last time (except for changes in the values returned by the LTA Data Mall APIs), and there won't be any leftover "stuff" from the previous run causing problems. It also means that you can easily hand the script off to someone else who has Python/Requests installed and they can run it with one command! That __name__ stuff is to let us import the other utilities from that file (e.g. headers) if we want to use them for other things without waiting for results to be filled.
If you want to use this interactively, you actually still can, just by running from run import * in the IPython console:
In [1]: from run import *
In [2]: requests.get(
...: "http://datamall2.mytransport.sg/ltaodataservice/BusStops",
...: headers=headers
...: )
Out[2]: <Response [200]>
The next thing to do is to take that while loop and putting it in a function, so we can easily use the same while-loop to make requests agains any of the LTA Data Mall APIs. For example, if we wanted to ask the api about BusServices instead of BusStops, by default we still only get 50 entries:
In [3]: from run import *
In [4]: requests.get(
"http://datamall2.mytransport.sg/ltaodataservice/BusServices",
headers=headers
)
Out[4]: <Response [200]>
In [5]: len(Out[4].json()['value'])
Out[5]: 50
We can easily move all that logic into a function, here called fetch_all:
import requests
headers = {
'AccountKey': 'rmgDEFTiRRfcNeD8GbHqf8==',
'UniqueUserID': '8ecabd56-08a2-e843-0a7a-9944dccf124a',
'accept': 'application/json'
}
def fetch_all(url):
results = []
while True:
new_results = requests.get(
url,
headers=headers,
params={'$skip': len(results)}
).json()['value']
if new_results == []:
break
else:
results += new_results
return results
if __name__ == "__main__":
stops = fetch_all("http://datamall2.mytransport.sg/ltaodataservice/BusStops")
print len(stops)
services = fetch_all("http://datamall2.mytransport.sg/ltaodataservice/BusServices")
print len(services)
Running this, we get:
haoyi-mbp:test haoyi$ python run.py
5260
550
It seems there are 550 distinct bus services? We can do a similar sanity check here as we did earlier to make sure the data is correct. Here I'm loading the data in the IPython shell, seeing what keys are available, and checking to see what 'ServiceNo' contains:
In [1]: from run import *
In [2]: services = fetch_all("http://datamall2.mytransport.sg/ltaodataservice/BusServices")
In [3]: services[0].keys()
Out[3]:
[u'Category',
u'ServiceNo',
u'Direction',
u'DestinationCode',
u'AM_Offpeak_Freq',
u'LoopDesc',
u'PM_Offpeak_Freq',
u'Operator',
u'AM_Peak_Freq',
u'PM_Peak_Freq',
u'OriginCode']
In [4]: [s["ServiceNo"] for s in services]
Out[4]:
[u'10',
u'10',
u'100',
u'100',
u'101',
u'102',
u'103',
u'103',
u'105',
u'105',
u'107',
u'107',
u'107M',
u'109',
u'109',
u'10e',
u'10e',
u'11',
u'111',
u'112',
...
Seems reasonable! For brevity I won't explore this data much deeper, but if you're following it's totally worth spending some time to repeat the Sanity Checking we did on the /BusStops data-set to make sure it's what you want.
We've not got our code into a nice script: we can either run it to fetch both bus stops and services, or import it in the IPython shell to let us fetch whatever we want, or deal with the data however we want, interactively.
Expansion
Now that we've got our code in order, let's look at what we want to do with it. Let's look back at our original project plan:
to write a trip planner to find the shortest bus trip between two points on the island
Not so much a "plan" as an "idea", but it'll do for now. How deep we go into this project depends on how much time we have, but at the very least the first few options might be, in increasing order of complexity:
- Find the shortest path from bus stop A to the stop B, in number of stops
- Find the shortest path from bus stop A to the stop B, in distance travelled
- Find the shortest path from bus stop A to the stop B, in expected time taken including expected waiting time for each bus.
Option 1 would be simplest: you just count the number of stops each route would take you Option 2 we would take into consideration how far away the stops were to each other, while Option 3 would include the waiting time for the bus, either in aggregate ("Bus 101 comes every 11-17 minutes") or using the real-time data ("Bus 101 will be at bus stop 01234 in 4 minutes and 22 minutes").
Number of Stops
Before we do anything fancy, let's get the "number of stops" finder working first. The first "obvious" thing we'd need is to know which buses stop at which stops, in what order. According to the Data Mall API User Guide, this can be found in the /BusRoutes endpoint
In [1]: from run import *
In [2]: routes = fetch_all("http://datamall2.mytransport.sg/ltaodataservice/BusRoutes")
This fetch_all takes a while! On relatively fast wifi it took me 63 seconds, far more than the 2-10s that earlier fetches took. It makes sense when you look at the size of the aggregate result:
In [3]: len(routes)
Out[3]: 23494
It turns out that there's one entry for every service, for every stop it stops at. This is more obvious when we look at a sample:
In [4]: routes[0]
Out[4]:
{u'BusStopCode': u'75009',
u'Direction': 1,
u'Distance': 0,
u'Operator': u'SBST',
u'SAT_FirstBus': u'0500',
u'SAT_LastBus': u'2300',
u'SUN_FirstBus': u'0500',
u'SUN_LastBus': u'2300',
u'ServiceNo': u'10',
u'StopSequence': 1,
u'WD_FirstBus': u'0500',
u'WD_LastBus': u'2300'}
A single 'ServiceNo', a single 'BusStopCode', and a 'StopSequence' indicating its position along the route. We could query an example bus service to see what stops it makes:
In [5]: [r for r in routes if r['ServiceNo'] == '111']
Out[5]:
[{u'BusStopCode': u'11009',
u'Direction': 1,
u'Distance': 0,
u'Operator': u'SBST',
u'SAT_FirstBus': u'0600',
u'SAT_LastBus': u'2400',
u'SUN_FirstBus': u'0600',
u'SUN_LastBus': u'2400',
u'ServiceNo': u'111',
u'StopSequence': 1,
u'WD_FirstBus': u'0600',
u'WD_LastBus': u'2400'},
{u'BusStopCode': u'11359',
u'Direction': 1,
u'Distance': 0.2,
u'Operator': u'SBST',
u'SAT_FirstBus': u'0601',
u'SAT_LastBus': u'0001',
u'SUN_FirstBus': u'0601',
u'SUN_LastBus': u'0001',
u'ServiceNo': u'111',
u'StopSequence': 2,
u'WD_FirstBus': u'0601',
u'WD_LastBus': u'0001'},
...
Perhaps not very meaningful, since nobody memorizes 'BusStopCode's, but we can easily cross-reference it with the data we fetched from the /BusStop API to give them meaningful descriptions. First we need a dictionary to let us quickly look up a bus stop by its code:
In [6]: stops = fetch_all("http://datamall2.mytransport.sg/ltaodataservice/BusStops")
In [7]: stops[0]
Out[7]:
{u'BusStopCode': u'01012',
u'Description': u'Hotel Grand Pacific',
u'Latitude': 1.29684825487647,
u'Longitude': 103.85253591654006,
u'RoadName': u'Victoria St'}
In [8]: stop_map = {stop['BusStopCode']: stop for stop in stops}
This creates a stop_map dictionary we can use to quickly-and-easily look up the "full" data (including its human-readable Description) of a bus stop based on its BusStopCode
Then we can apply it to the routes list comprehension earlier, to give names to all the stops that the service 111 stops along:
In [9]: [stop_map[r['BusStopCode']]['Description'] for r in routes if r['ServiceNo'] == '111']
Out[9]:
[u'Ghim Moh Ter',
u'Blk 12',
u'Blk 43',
u'Blk 8',
u"C'wealth Stn",
u'Aft Ch Of Our Saviour',
u'Queenstown Stn',
u'Blk 53A CP',
u'Opp SM Motors Ctr',
u'Opp SIS Bldg',
u'Aft Margaret Dr',
u'Opp Chatsworth Rd',
u'Aft Rochalie Dr',
u'British High Comm',
...
In [10]: len(Out[9])
Out[10]: 54
54 stops, starting in Ghim Moh, through Commonweatlth (C'wealth), Queenstown, and eventually back to Ghim Moh. Looks correct!
Caching
Before we go any further, let's address the fact that /BusRoutes takes over a minute to load. We know two things:
- Waiting >1 minute for your code to load data before it runs really sucks, especially when it's buggy and you're trying to figure out what's wrong.
- Bus routes do not change very often
Given that, we should be able to save the bus routes we loaded earlier to a file, and just load them from the file next time! Perhaps once a day or once a week we might need to re-download all the routes, but we certainly don't need to do that every time.
With Python, dumping the data structure back to JSON on disk is easy:
In [11]: import json
In [12]: with open("routes.json", "w") as f:
....: f.write(json.dumps(routes))
While we're at it, we might as well dump the /BusStops and /BusServices responses too:
In [14]: with open("stops.json", "w") as f:
....: f.write(json.dumps(stops))
....:
In [15]: services = fetch_all("http://datamall2.mytransport.sg/ltaodataservice/BusServices")
In [16]: with open("services.json", "w") as f:
....: f.write(json.dumps(services))
....:
Next time, we can just json.loads(open("routes.json").read()) and have it all back instantly without needing to wait 1 minute to download.
An Application
Now we know
- What all the bus stops are and what they're called
- Which bus routes connect which stops to which other stops
It should be relatively easy to write a program that searches for the shortest route between two bus stops, in terms of number of in-between stops. If we had a trip.py file, we may expect someone to run it via
python trip.py "Opp Orchard Stn" "Changi Village Ter"
And have the program print out what buses to take to which stops. Maybe later we can make a fancy web interface or mobile app, but for now a basic command-line program will do. Before we even think about route-finding, let's make a basic program that takes in user input, loads the data from disk, and does something (anything!) with it. This would ensure we have all the framework in place to put in the fancy trip-planning algorithms later.
To begin with, in Python you read the arguments from the command line with import sys; sys.argv[1]. We can make a minimal trip.py to verify this:
import sys
start = sys.argv[1]
end = sys.argv[2]
print (start, end)
Which runs and just echos out the two parameters:
haoyi-mbp:test haoyi$ python trip.py "Opp Orchard Stn" "Changi Village Ter"
('Opp Orchard Stn', 'Changi Village Ter')
Since we have the bus stops, bus services and bus routes already downloaded as JSON files on disk, we can load them quickly and look up e.g. their "BusStopCode"s:
import sys
import json
start = sys.argv[1]
end = sys.argv[2]
stops = json.loads(open("stops.json").read())
stop_desc_map = {stop["Description"]: stop for stop in stops}
print (stop_desc_map[start]["BusStopCode"], stop_desc_map[end]["BusStopCode"])
haoyi-mbp:test haoyi$ python trip.py "Opp Orchard Stn" "Changi Village Ter"
(u'09022', u'99009')
Although we have the information of what the route of each bus service is, it's in a rather odd format: each service and bus stop is its own entry in one huge list. It would be much more convenient if we could quickly look up what stops were along which route. To do so, we'd need to convert the flat list into a dictionary, with each key being the "ServiceNo" and "Direction" and each value being a list of stops that route stops at.
import sys
import json
start = sys.argv[1]
end = sys.argv[2]
stops = json.loads(open("stops.json").read())
stop_desc_map = {stop["Description"]: stop for stop in stops}
stop_code_map = {stop["BusStopCode"]: stop for stop in stops}
services = json.loads(open("services.json").read())
routes = json.loads(open("routes.json").read())
routes_map = {}
for route in routes:
key = (route["ServiceNo"], route["Direction"])
if key not in routes_map:
routes_map[key] = []
routes_map[key] += [route]
print [stop_code_map[r["BusStopCode"]]["Description"] for r in routes_map[("111", 1)]]
print (stop_desc_map[start]["BusStopCode"], stop_desc_map[end]["BusStopCode"])
This works:
haoyi-mbp:test haoyi$ python trip.py "Opp Orchard Stn" "Changi Village Ter"
[u'Ghim Moh Ter', u'Blk 12', u'Blk 43', u'Blk 8', u"C'wealth Stn", u'Aft Ch Of Our Saviour', u'Queenstown Stn', u'Blk 53A CP', u'Opp SM Motors Ctr', u'Opp SIS Bldg', u'Aft Margaret Dr', u'Opp Chatsworth Rd', u'Aft Rochalie Dr', u'British High Comm', u'Aft Tomlinson Rd', u'Delfi Orchard', u'Royal Thai Embassy', u'Lucky Plaza', u'Midpoint Orchard', u"Concorde Hotel S'pore", u'Dhoby Ghaut Stn', u'Rendezvous Grand Hotel', u'NTUC Income Ctr', u'Raffles Hotel', u'Suntec Convention Ctr', u'Opp Millenia Twr', u'Opp The Ritz-Carlton', u'Seating Gallery', u'The Esplanade', u'Capitol Bldg', u'SMU', u'YMCA', u'Dhoby Ghaut Stn', u'Winsland Hse', u'Somerset Stn', u'Natl Youth Council', u'Opp Orchard Stn', u'Opp Four Seasons Hotel', u'Bef Tomlinson Rd', u'Grange Residences', u'Opp British High Comm', u'Bef Rochalie Dr', u'Bef Chatsworth Rd', u"Crescent Girls' Sch", u'SIS Bldg', u'Aft SM Motors Ctr', u'Queens Condo', u'Queenstown Stn', u'Blk 42', u"C'wealth Stn", u'Opp Blk 7B', u'Opp Blk 43', u'Blk 13', u'Ghim Moh Ter']
(u'09022', u'99009')
Though we could use the pprint module to make it more readable:
import sys
import json
import pprint
start = sys.argv[1]
end = sys.argv[2]
stops = json.loads(open("stops.json").read())
services = json.loads(open("services.json").read())
routes = json.loads(open("routes.json").read())
stop_desc_map = {stop["Description"]: stop for stop in stops}
stop_code_map = {stop["BusStopCode"]: stop for stop in stops}
routes_map = {}
for route in routes:
key = (route["ServiceNo"], route["Direction"])
if key not in routes_map:
routes_map[key] = []
routes_map[key] += [route]
pprint.pprint(
[stop_code_map[r["BusStopCode"]]["Description"] for r in routes_map[("111", 1)]]
)
print (stop_desc_map[start]["BusStopCode"], stop_desc_map[end]["BusStopCode"])
haoyi-mbp:test haoyi$ python trip.py "Opp Orchard Stn" "Changi Village Ter"
[u'Ghim Moh Ter',
u'Blk 12',
u'Blk 43',
u'Blk 8',
u"C'wealth Stn",
u'Aft Ch Of Our Saviour',
u'Queenstown Stn',
u'Blk 53A CP',
u'Opp SM Motors Ctr',
u'Opp SIS Bldg',
u'Aft Margaret Dr',
u'Opp Chatsworth Rd',
...]
(u'09022', u'99009')
Algorithms
We now have something that can be run from the command line that runs our code to do stuff. We've worked with the API and downloaded a local copy of the data we're interested in for now so we can work with it quickly, and know how to fetch more data from other endpoints if necessary. Our program loads the data, takes user input, and does something with it, even though right now it's just trivially looking up the BusStopCodes of the stops the user inputed, and performing some hardcoded querying of the loaded data to find the stops along Bus 111.
The next step is to finally make it actually do the thing we wanted to do: planning trips between bus stops!
Breadth First Search
Now we have the data in convenient formats, we're on to the next question: how, given a list of bus stops and a list of bus services that move between them, can we find a trip between two bus stops that minimizes the number of bus stops you cross? This can be rephrased as "given a number of nodes and edges between them, find the path between two nodes with the smallest number of edges". Lucky for us, there are many many known algorithms for this, the most common of which is the Breadth First Search. This is an intro-to-computer-science level algorithm, and examples can be found all over, e.g. this one on Stackoverflow
# graph is in adjacent list representation
graph = {
'1': ['2', '3', '4'],
'2': ['5', '6'],
'5': ['9', '10'],
'4': ['7', '8'],
'7': ['11', '12']
}
def bfs(graph, start, end):
# maintain a queue of paths
queue = []
# push the first path into the queue
queue.append([start])
while queue:
# get the first path from the queue
path = queue.pop(0)
# get the last node from the path
node = path[-1]
# path found
if node == end:
return path
# enumerate all adjacent nodes, construct a new path and push it into the queue
for adjacent in graph.get(node, []):
new_path = list(path)
new_path.append(adjacent)
queue.append(new_path)
print bfs(graph, '1', '11')
This example isn't quite optimal
- It's using
list.pop(0), which is O(n), instead of using a queue where de-queueing is O(1)
- It does not maintain a "seen" set to avoid searching the same nodes multiple times.
Whether that is actually a problem or not depends on the data-set in question. Clearly in the toy network provided, it works. What happens if you feed in our bus-stop network?
It turns out that you can take our earlier route_map and convert it into the same graph format that this code expects relatively straightforwardly:
graph = {}
for service, path in routes_map.items():
for route_index in range(len(path) - 1):
key = path[route_index]["BusStopCode"]
if key not in graph:
graph[key] = []
graph[path[route_index]["BusStopCode"]].append(path[route_index + 1]["BusStopCode"])
This generates a graph that looks like:
{
u'01012': {u'01013', u'01112', u'01113'},
u'01013': {u'01112', u'01113'},
u'01019': {u'02049', u'04159'},
u'01029': {u'04111', u'04167', u'04168'},
u'01039': {u'01029'},
u'01059': {u'01119'},
u'01109': {u'07551'},
u'01112': {u'01113', u'01121', u'07551'},
u'01113': {u'01121'},
u'01119': {u'01019'},
u'01121': {u'01211', u'07331'},
u'01129': {u'01059'},
...
}
Which seems reasonable: spot checking it, stop 01059 is "Bugis Stn", and the only stop it has an edge to is 1119, or "Bugis Junction". Although there are many buses out of "Bugis Stn", all of them go straight to "Bugis Junction", and so the fact that it only has one edge out is correct. In later iterations we may care about how many buses go between stops, or how long they take, how long's the wait, or how frequent they are, but for now we're just ignoring that and counting "one stop" as "one stop"
It turns out we can re-use this example almost entirely: we just need to feed in our own graph data structure. The entire code, excluding the code for pre-downloading and saving the JSON files, is below:
import sys
import json
import pprint
start = sys.argv[1]
end = sys.argv[2]
print "loading JSON"
stops = json.loads(open("stops.json").read())
services = json.loads(open("services.json").read())
routes = json.loads(open("routes.json").read())
print "Initializing tables"
stop_desc_map = {stop["Description"]: stop for stop in stops}
stop_code_map = {stop["BusStopCode"]: stop for stop in stops}
routes_map = {}
for route in routes:
key = (route["ServiceNo"], route["Direction"])
if key not in routes_map:
routes_map[key] = []
routes_map[key] += [route]
print "Initializing Graph"
graph = {}
for service, path in routes_map.items():
for route_index in range(len(path) - 1):
key = path[route_index]["BusStopCode"]
if key not in graph:
graph[key] = set()
graph[path[route_index]["BusStopCode"]].add(path[route_index + 1]["BusStopCode"])
print "Running BFS"
def bfs(graph, start, end):
# maintain a queue of paths
queue = []
# push the first path into the queue
queue.append([start])
while queue:
# get the first path from the queue
path = queue.pop(0)
# get the last node from the path
node = path[-1]
# path found
if node == end:
return path
# enumerate all adjacent nodes, construct a new path and push it into the queue
for adjacent in graph.get(node, []):
new_path = list(path)
new_path.append(adjacent)
queue.append(new_path)
pprint.pprint(
bfs(graph, stop_desc_map[start]["BusStopCode"], stop_desc_map[end]["BusStopCode"])
)
You can run this, and find... it never terminates. It reaches, the "Running BFS" step, and then spends forever running the BFS. If you add a print statement to see how long the path is, it never goes much past 6 or 7 deep. It seems that the earlier inefficiencies we found in the search algorithm really are, in fact, slowing things down. You can leave it running for an hour and, while it's vigorously searching, it will never find a path between two bus stops more than a handful of stops apart!
Luckily it's relatively straightforward swapping out the [] list for a Queue to make de-queueing efficient, and adding a seen set to avoid searching each node more than once:
haoyi-mbp:test haoyi$ git diff
diff --git a/trip.py b/trip.py
index 9eb8380..186cb98 100644
--- a/trip.py
+++ b/trip.py
@@ -48,23 +48,29 @@ for service, path in routes_map.items():
print "Running BFS"
def bfs(graph, start, end):
+ from Queue import Queue
+ seen = set()
# maintain a queue of paths
- queue = []
+ queue = Queue()
# push the first path into the queue
- queue.append([start])
+ queue.put([start])
while queue:
# get the first path from the queue
- path = queue.pop(0)
+ path = queue.get()
+
# get the last node from the path
node = path[-1]
# path found
if node == end:
return path
+ if node in seen:
+ continue
+ seen.add(node)
# enumerate all adjacent nodes, construct a new path and push it into the queue
for adjacent in graph.get(node, []):
new_path = list(path)
new_path.append(adjacent)
- queue.append(new_path)
+ queue.put(new_path)
And that makes the code finish almost instantly, printing e.g.
haoyi-mbp:test haoyi$ python trip.py "Opp Orchard Stn" "Changi Village Ter"
loading JSON
Initializing tables
Initializing Graph
Running BFS
[u'09022',
u'13199',
u'E1301',
u'13191',
u'09212',
u'09213',
u'E4022',
u'40231',
u'PIE',
u'ECP',
u'95151',
...
u'99011',
u'99021',
u'99031',
u'99041',
u'99139',
u'99009']
Since I think in "Description"s better than in "BusStopCode"s, I'll print out all those instead:
path = bfs(graph, stop_desc_map[start]["BusStopCode"], stop_desc_map[end]["BusStopCode"])
pprint.pprint([stop_code_map[stop_code]["Description"] for stop_code in path ])
haoyi-mbp:test haoyi$ python trip.py "Opp Orchard Stn" "Changi Village Ter"
loading JSON
Initializing tables
Initializing Graph
Running BFS
[u'Opp Orchard Stn',
u'Opp Paterson Lodge',
u'Non Stop',
u'Paterson Lodge',
u'Royal Plaza On Scotts',
u'Thong Teck Bldg',
u'Non Stop',
u'Raffles Town Club',
u'Express',
u'Express',
u'Airport Police Stn',
...
u'LP 80',
u'Bef Sch Of Commando',
u'Bef Cranwell Rd',
u'Opp Maranatha B-P Ch',
u'Aft Changi Golf Course',
u'Blk 5',
u'Changi Village Ter']
Now we know what the shortest set of bus stops is, but we don't actually know what buses will get us along that set of bus stops! It's pretty easy to write code that will figure that out for us though:
path = bfs(graph, stop_desc_map[start]["BusStopCode"], stop_desc_map[end]["BusStopCode"])
def find_service(i):
for (service, direction), route in routes_map.items():
for j in range(len(route)-1):
if path[i] == route[j]["BusStopCode"] and path[i+1] == route[j+1]["BusStopCode"]:
return (
service,
stop_code_map[path[i]]["Description"],
stop_code_map[path[i + 1]]["Description"]
)
for i in range(len(path) - 1):
print find_service(i)
print len(path), "stops"
- Note: this is a relatively hacky way of reverse-engineering which buses to take between the various stops, as the current algorithm doesn't keep track of what services it took: it only knows what stops are connected with what other stops. Furthermore, since the current algorithm doesn't take into account the time taken to transfer buses, it will definitely end up with a route with far too many transfers. This is something we'll fix later when we teach it to understand Transfer Costs.
Nevertheless, running this gets us an acceptable approximation of what bus services we could take to follow that route.
haoyi-mbp:test haoyi$ python trip.py "Opp Orchard Stn" "Changi Village Ter"
loading JSON
Initializing tables
Initializing Graph
Running BFS
(u'14', u'Opp Orchard Stn', u'Opp Paterson Lodge')
(u'NR5', u'Opp Paterson Lodge', u'Non Stop')
(u'NR6', u'Non Stop', u'Paterson Lodge')
(u'5', u'Paterson Lodge', u'Royal Plaza On Scotts')
(u'NR3', u'Royal Plaza On Scotts', u'Thong Teck Bldg')
(u'971E', u'Thong Teck Bldg', u'Non Stop')
(u'971E', u'Non Stop', u'Raffles Town Club')
(u'NR3', u'Raffles Town Club', u'Express')
(u'858', u'Express', u'Express')
(u'858', u'Express', u'Airport Police Stn')
(u'34', u'Airport Police Stn', u'Bef Changi Airport PTB3')
(u'34', u'Bef Changi Airport PTB3', u'Changi Airport PTB3')
(u'34', u'Changi Airport PTB3', u'Changi Airport PTB1')
(u'34', u'Changi Airport PTB1', u'Changi Airport PTB2')
(u'34', u'Changi Airport PTB2', u'Aft Changi Airport PTB2')
(u'34', u'Aft Changi Airport PTB2', u'Near SATS Flight Kitchen')
(u'34', u'Near SATS Flight Kitchen', u'At Track 33 Int')
(u'53', u'At Track 33 Int', u'Blk 149A')
(u'59', u'Blk 149A', u'Blk 275')
(u'59', u'Blk 275', u'Aft Pasir Ris Dr 3')
(u'59', u'Aft Pasir Ris Dr 3', u'Opp Loyang Valley')
(u'59', u'Opp Loyang Valley', u'Loyang Ind Est')
(u'59', u'Loyang Ind Est', u'Bef Loyang Way')
(u'59', u'Bef Loyang Way', u'Opp Engine Test Facility')
(u'59', u'Opp Engine Test Facility', u'LP 80')
(u'59', u'LP 80', u'Bef Sch Of Commando')
(u'59', u'Bef Sch Of Commando', u'Bef Cranwell Rd')
(u'59', u'Bef Cranwell Rd', u'Opp Maranatha B-P Ch')
(u'59', u'Opp Maranatha B-P Ch', u'Aft Changi Golf Course')
(u'59', u'Aft Changi Golf Course', u'Blk 5')
(u'59', u'Blk 5', u'Changi Village Ter')
30 stops
Looks like it's asking us to take a mish-mash of routes at the start, then bus 34 from the 'Airport Polic Stn' to 'Near SATS Flight Kitchen', then 59 to 'Changi Village Ter'. It's not a very good route, but it's a route!
Success!
Improvements
There are a bunch of obvious limitations with the above trip planner:
-
It picks buses which aren't even running at the same time, like the NR5 services which only run at night!
-
It makes you change between lots of buses to try and minimize the number of stops you cross, without counting the time wasted waiting for buses.
-
It doesn't count how far the bus stops are from each other; some are closer than others
Luckily, all of these are solvable. The average wait between buses is available as part of the /BusServices endpoint that we've saved into services.json, as the various _Freq fields:
In [3]: import json
In [4]: services = json.loads(open("services.json").read())
In [5]: services[0]
Out[5]:
{u'AM_Offpeak_Freq': u'7-15',
u'AM_Peak_Freq': u'10-14',
u'Category': u'TRUNK',
u'DestinationCode': u'16009',
u'Direction': 1,
u'LoopDesc': u'',
u'Operator': u'SBST',
u'OriginCode': u'75009',
u'PM_Offpeak_Freq': u'13-18',
u'PM_Peak_Freq': u'13-15',
u'ServiceNo': u'10'}
While the distance between bus stops and the first/last bus for each service at each stop is available under the /BusRoutes endpoint or routes.json file:
In [6]: routes = json.loads(open("routes.json").read())
In [7]: routes[0]
Out[7]:
{u'BusStopCode': u'75009',
u'Direction': 1,
u'Distance': 0,
u'Operator': u'SBST',
u'SAT_FirstBus': u'0500',
u'SAT_LastBus': u'2300',
u'SUN_FirstBus': u'0500',
u'SUN_LastBus': u'2300',
u'ServiceNo': u'10',
u'StopSequence': 1,
u'WD_FirstBus': u'0500',
u'WD_LastBus': u'2300'}
Which contains the _FirstBus and _LastBus for weekdays and weekends, as well as the 'Distance' along the route each stop is which can be subtracted to find the distance between stops.
Dijkstra's Algorithm
The previous version of our trip planner used a Breadth First Search, which works great if every edge between two bus stops has the same cost. If the cost of each edge varies, we need to use something more flexible: lucky for us, there are existing algorithms for this!
One of which that students learn in their first Algorithms class is Dijkstra's Algorithm. It is essentially identical to a breadth first search, except that instead of using a simple Queue to organize the nodes to visit, it uses a Priority Queue. The end result is instead of exploring the nodes in the order that they are seen, Dijkstra's explores them in order of how far away they are from the starting node according to an arbitrary "cost" function. If we use "distance between bus stops" as the cost of each edge, we'll find the shortest route to take, in terms of kilometers traveled instead of bus-stops crossed.
To do this, we will change our graph to instead of storing a dictionary of:
{bus_stop_code: {adjacent_bus_stop_codes}}
To instead store:
{bus_stop_code: {adjacent_bus_stop_codes: distance_to_adjacent_bus_stop}}
Via:
@@ -34,21 +30,27 @@ for service, path in routes_map.items():
for route_index in range(len(path) - 1):
key = path[route_index]["BusStopCode"]
if key not in graph:
- graph[key] = set()
- graph[path[route_index]["BusStopCode"]].add(path[route_index + 1]["BusStopCode"])
+ graph[key] = {}
+ curr_route_stop = path[route_index]
+ next_route_stop = path[route_index + 1]
+ curr_distance = curr_route_stop["Distance"]
+ next_distance = next_route_stop["Distance"]
+ distance = next_distance - curr_distance
+ assert distance >= 0, (curr_route_stop, next_route_stop)
+ graph[curr_route_stop["BusStopCode"]][next_route_stop["BusStopCode"]] = distance
print "Running BFS"
As you can see, instead of constructing the a set() for the "next stops" for each bus stop we now construct a dictionary {} which will contain the next stops along with the distance to each one.
- Note: The
"Distance" attribute on each item is the distance of that stop from the start of that service's route, and not the distance from the previous stop. Thus if we want the distance from one stop to the next, we need to subtract the two "Distance" attributes to get the distance the bus would need to travel between the stops.
At the same time, we need to modify our bfs to use a Priority Queue, which is the Python heapq module, to turn it into a dijkstras search:
print "Running BFS"
-def bfs(graph, start, end):
- from Queue import Queue
+def dijkstras(graph, start, end):
+ import heapq
seen = set()
# maintain a queue of paths
- queue = Queue()
+ queue = []
# push the first path into the queue
- queue.put([start])
+ heapq.heappush(queue, (0, [start]))
while queue:
# get the first path from the queue
- path = queue.get()
+ (curr_distance, path) = heapq.heappop(queue)
# get the last node from the path
node = path[-1]
@@ -59,12 +61,12 @@ def bfs(graph, start, end):
continue
seen.add(node)
# enumerate all adjacent nodes, construct a new path and push it into the queue
- for adjacent in graph.get(node, []):
+ for adjacent, distance in graph.get(node, {}).items():
new_path = list(path)
new_path.append(adjacent)
- queue.put(new_path)
+ heapq.heappush(queue, (curr__distance, new_path))
-path = bfs(graph, stop_desc_map[start]["BusStopCode"], stop_desc_map[end]["BusStopCode"])
+path = dijkstras(graph, stop_desc_map[start]["BusStopCode"], stop_desc_map[end]["BusStopCode"])
This is a relatively shallow conversion: we replace the Queue with heapq, and rename all the methods calls to use the heapq equivalents. In order to ensure the heapq sorts things in the correct order, we store tuples of
(total_distance, path)
As each element in the heapq.
This looks correct, but if you run this, you will find it crashes:
haoyi-mbp:test haoyi$ python trip.py "Opp Orchard Stn" "Changi Village Ter"
loading JSON
Initializing tables
Initializing Graph
Traceback (most recent call last):
File "trip.py", line 37, in <module>
distance = next_distance - curr_distance
TypeError: unsupported operand type(s) for -: 'NoneType' and 'float'
How is that?
More Sanity Checking
Presumably some of our 'Distance' fields are None instead of having a sensible value. We can fix that by defaulting to 0 if it's not found:
haoyi-mbp:test haoyi$ git diff
diff --git a/trip.py b/trip.py
index 49f1ce2..a274b69 100644
--- a/trip.py
+++ b/trip.py
@@ -39,8 +39,8 @@ for service, path in routes_map.items():
graph[key] = {}
curr_route_stop = path[route_index]
next_route_stop = path[route_index + 1]
- curr_distance = curr_route_stop["Distance"]
- next_distance = next_route_stop["Distance"]
+ curr_distance = curr_route_stop["Distance"] or 0
+ next_distance = next_route_stop["Distance"] or curr_distance
distance = next_distance - curr_distance
assert distance >= 0, (curr_route_stop, next_route_stop)
graph[curr_route_stop["BusStopCode"]][next_route_stop["BusStopCode"]] = distance
But we still find it fails the next_distance - curr_distance check:
haoyi-mbp:test haoyi$ python trip.py "Opp Orchard Stn" "Changi Village Ter"
loading JSON
Initializing tables
Initializing Graph
Traceback (most recent call last):
File "trip.py", line 38, in <module>
assert distance >= 0, (curr_distance, next_distance)
AssertionError: (9.1, 1.3)
How odd, why is one stop at distance 9.1 and the next at distance 1.3? In order to try We can make our assert more verbxose:
haoyi-mbp:test haoyi$ git diff
diff --git a/trip.py b/trip.py
index 07ce374..031df9f 100644
--- a/trip.py
+++ b/trip.py
@@ -36,7 +36,7 @@ for service, path in routes_map.items():
curr_distance = curr_route_stop["Distance"] or 0
next_distance = next_route_stop["Distance"] or curr_distance_
distance = next_distance - curr_distance
- assert distance >= 0, (curr_distance, next_distance)
+ assert distance >= 0, (curr_route_stop, next_route_stop)
graph[curr_route_stop["BusStopCode"]][next_route_stop["BusStopCode"]] = distance
print "Running BFS"
In which case we get:
AssertionError: ({
u'ServiceNo': u'34',
u'Direction': 1,
u'Distance': 9.1,
u'SUN_LastBus': u'0006',
u'StopSequence': 4,
u'WD_LastBus': u'0009',
u'Operator': u'SBST',
u'BusStopCode': u'76059',
u'SAT_LastBus': u'0006',
u'WD_FirstBus': u'0534',
u'SUN_FirstBus': u'0547',
u'SAT_FirstBus': u'0549'
}, {
u'ServiceNo': u'34',
u'Direction': 1,
u'Distance': 1.3,
u'SUN_LastBus': u'2347',
u'StopSequence': 4,
u'WD_LastBus': u'2348',
u'Operator': u'SBST',
u'BusStopCode': u'65079',
u'SAT_LastBus': u'2348',
u'WD_FirstBus': u'0533',
u'SUN_FirstBus': u'0532',
u'SAT_FirstBus': u'0532'
})
That's really odd! We have two stops by service '34', in the same direction (1), both with 'StopSequence': 4, but they appear to be stopping at different bus stops (76059 and 65079) and have different _FirstBus/_LastBus times! How could that be? Looking up this bus online, it seems that these are two valid stops along vastly different sections of the bus route. Curious, we may decide to investigate the data further to see what's up. We can easily load it into the IPython shell:
In [1]: import json
In [2]: routes = json.loads(open("routes.json").read())
In [3]: routes_map = {}
In [4]: for route in routes:
key = (route["ServiceNo"], route["Direction"])
if key not in routes_map:
routes_map[key] = []
routes_map[key] += [route]
...:
In [5]: len(routes_map[('34', 1)])
Out[5]: 51
In [6]: routes_map[('34', 1)][0].keys()
Out[6]:
[u'ServiceNo',
u'Direction',
u'Distance',
u'SUN_LastBus',
u'StopSequence',
u'WD_LastBus',
u'Operator',
u'BusStopCode',
u'SAT_LastBus',
u'WD_FirstBus',
u'SUN_FirstBus',
u'SAT_FirstBus']
Since we know that 'StopSequence' and 'Distance' are the weird things, let's pull up both those attributes for bus 34 to see what they look like:
In [7]: [(r["StopSequence"], r["Distance"]) for r in routes_map[('34', 1)]]
Out[7]:
[(1, 0),
(2, 0.6),
(3, 1),
(4, 9.1),
(4, 1.3),
(5, 1.7),
(6, 5.7),
(7, 6.1),
(8, 6.5),
(9, 7),
(10, 7.3),
(11, 7.9),
(12, 8.3),
(13, 8.6),
(15, 9.6),
(16, 10.1),
(17, 10.6),
(18, 11),
(19, 11.4),
(20, 12),
(21, 12.3),
(22, None),
(23, 16.6),
(24, 17.1),
(25, 18.5),
(26, 19.3),
(27, 20.1),
(28, 21.2),
(29, 21.9),
(30, None),
(31, 26.4),
(32, 26.7),
(33, 27.3),
(34, 27.8),
(35, 28.3),
(36, 28.8),
(37, 29.4),
(38, 29.9),
(39, 30.4),
(40, 30.8),
(41, 31.1),
(42, 31.7),
(43, 32),
(44, 32.6),
(45, 33),
(46, 33.3),
(47, 37.3),
(48, 37.8),
(49, 38.1),
(50, 38.4),
(51, 38.9)]
That's really odd! We have a bunch of Nones where the dataset doesn't give us the ditance, and we also have two 4s for 'StopSequence' and do not have a stop 14 at all! Obviously someone made a mistake in the data and called stop #14 stop #4. But what can we do about it?
Working Around
The first thing to do is to work around it and hope not too may other issues crop up:
haoyi-mbp:test haoyi$ git diff
diff --git a/trip.py b/trip.py
index 031df9f..49f1ce2 100644
--- a/trip.py
+++ b/trip.py
@@ -21,12 +21,18 @@ for route in routes:
key = (route["ServiceNo"], route["Direction"])
if key not in routes_map:
routes_map[key] = []
-
+ # hack around broken data
+ if (route["StopSequence"] == 4
+ and route["Distance"] == 9.1
+ and key == ("34", 1)):
+ route["StopSequence"] = 14
routes_map[key] += [route]
print "Initializing Graph"
graph = {}
for service, path in routes_map.items():
+ # hack around broken data
+ path.sort(key = lambda r: r["StopSequence"])
for route_index in range(len(path) - 1):
key = path[route_index]["BusStopCode"]
if key not in graph:
The goal of this change is to manually fix the incorrect route item while we're building our routes_map. Not only do we need to change its StopSequence, we also need to re-sort things to make sure that the order the stops appear in matches up with the fixed StopSequence.
If we run it, we get a seemingly-valid route!
haoyi-mbp:test haoyi$ python trip.py "Opp Orchard Stn" "Changi Village Ter"
loading JSON
Initializing tables
Initializing Graph
Running BFS
(u'14', u'Opp Orchard Stn', u'Opp Paterson Lodge')
(u'54', u'Opp Paterson Lodge', u'Bef Zion Full Gospel Ch')
(u'564', u'Bef Zion Full Gospel Ch', u'The Trillium')
(u'564', u'The Trillium', u'Aft Furama RiverFront')
(u'564', u'Aft Furama RiverFront', u'Opp Maritime Hse')
(u'75', u'Opp Maritime Hse', u'Opp Sth Pt')
(u'75', u'Opp Sth Pt', u'Hub Synergy Pt')
(u'10', u'Hub Synergy Pt', u'Aft Capital Twr')
(u'10', u'Aft Capital Twr', u'Opp The Ogilvy Ctr')
(u'106', u'Opp The Ogilvy Ctr', u'The Sail')
(u'97', u'The Sail', u'Marina Bay Financial Ctr')
(u'513', u'Marina Bay Financial Ctr', u'Express')
(u'513', u'Express', u'Laguna Natl C. Club')
(u'513', u'Laguna Natl C. Club', u'Opp Global Logistics Ctr')
(u'513', u'Opp Global Logistics Ctr', u'DB Schenker')
(u'513', u'DB Schenker', u"Opp S'pore Expo")
(u'20', u"Opp S'pore Expo", u'Opp Expo Halls 1/2/3')
(u'12', u'Opp Expo Halls 1/2/3', u'Opp Expo Halls 4/5/6')
(u'24', u'Opp Expo Halls 4/5/6', u'Bef Tropicana Condo')
(u'5', u'Bef Tropicana Condo', u'Opp Changi Ct')
(u'5', u'Opp Changi Ct', u'Opp Mera Terr P/G')
(u'4N', u'Opp Mera Terr P/G', u'Blk 149A')
(u'59', u'Blk 149A', u'Blk 275')
(u'59', u'Blk 275', u'Aft Pasir Ris Dr 3')
(u'59', u'Aft Pasir Ris Dr 3', u'Opp Loyang Valley')
(u'59', u'Opp Loyang Valley', u'Loyang Ind Est')
(u'59', u'Loyang Ind Est', u'Bef Loyang Way')
(u'59', u'Bef Loyang Way', u'Opp Engine Test Facility')
(u'59', u'Opp Engine Test Facility', u'LP 80')
(u'59', u'LP 80', u'Bef Sch Of Commando')
(u'59', u'Bef Sch Of Commando', u'Bef Cranwell Rd')
(u'59', u'Bef Cranwell Rd', u'Opp Maranatha B-P Ch')
(u'59', u'Opp Maranatha B-P Ch', u'Aft Changi Golf Course')
(u'59', u'Aft Changi Golf Course', u'Blk 5')
(u'59', u'Blk 5', u'Changi Village Ter')
36 stops
As you can see, we found a route taking 36 stops instead of the 30 stop route the earlier trip-planner found. This is because we're now trying to minimize the distance traveled rather than the number of stops. Thus it makes sense that the number of stops would suffer slightly. We don't currently have a way to track what distance the routes actually cover, but we'll add that capability later.
Service Hours
Not every bus runs at every hour, but the above trip-planner does not know that. That is why it includes the 4N "Nite Owl" buses, as part of the overall route, when those are run at odd hours when most other buses aren't running. To do that, you have to make use of the _FirstBus and _LastBus properties available on each entry in /BusRoutes or routes.json:
In [2]: import json
In [3]: routes = json.loads(open("routes.json").read())
In [4]: routes[0]
Out[4]:
{u'BusStopCode': u'75009',
u'Direction': 1,
u'Distance': 0,
u'Operator': u'SBST',
u'SAT_FirstBus': u'0500',
u'SAT_LastBus': u'2300',
u'SUN_FirstBus': u'0500',
u'SUN_LastBus': u'2300',
u'ServiceNo': u'10',
u'StopSequence': 1,
u'WD_FirstBus': u'0500',
u'WD_LastBus': u'2300'}
Our strategy will be simple: ask the user to tell us what time he's making the trip, and ignore buses which are not running at that time! For now let's assume it's a weekday, and thus only care about WD_FirstBus/WD_LastBus. If we wanted to add support for SAT/SUN, we could do that later.
Here we make use of sys.argv[3] to get the desired time from the user, and compare it to the first_bus and last_bus to make sure the bus is active:
haoyi-mbp:test haoyi$ git diff
diff --git a/trip.py b/trip.py
index a274b69..ec77bab 100644
--- a/trip.py
+++ b/trip.py
@@ -4,6 +4,7 @@ import pprint
start = sys.argv[1]
end = sys.argv[2]
+current_time = int(sys.argv[3])
print "loading JSON"
@@ -18,6 +19,18 @@ stop_code_map = {stop["BusStopCode"]: stop for stop in stops}
routes_map = {}
for route in routes:
+ try:
+ first_bus = int(route["WD_FirstBus"])
+ last_bus = int(route["WD_LastBus"])
+ except:
+ continue
+ if first_bus <= last_bus:
+ if not (first_bus <= current_time <= last_bus):
+ continue
+ if first_bus > last_bus:
+ if (last_bus <= current_time <= first_bus):
+ continue
+
key = (route["ServiceNo"], route["Direction"])
if key not in routes_map:
routes_map[key] = []
Now, if we ask for a trip at 1700 hours or 5pm, we don't get any of those 4N Nite Owl buses:
haoyi-mbp:test haoyi$ python trip.py "Opp Orchard Stn" "Changi Village Ter" 1700
loading JSON
Initializing tables
Initializing Graph
Running BFS
(u'14', u'Opp Orchard Stn', u'Opp Paterson Lodge')
(u'54', u'Opp Paterson Lodge', u'Bef Zion Full Gospel Ch')
(u'54', u'Bef Zion Full Gospel Ch', u'Opp ERC Inst')
(u'54', u'Opp ERC Inst', u'Airview Twr')
(u'54', u'Airview Twr', u'Aft AA Ctr')
(u'54', u'Aft AA Ctr', u'Opp Mohd Sultan Rd')
(u'54', u'Opp Mohd Sultan Rd', u'Opp Liang Ct')
(u'54', u'Opp Liang Ct', u'Opp Clarke Quay')
(u'195', u'Opp Clarke Quay', u'Supreme Ct')
(u'195', u'Supreme Ct', u'Pan Pacific Hotel')
(u'97', u'Pan Pacific Hotel', u'Marina Ctr Ter')
(u'36', u'Marina Ctr Ter', u'Aft Raffles Blvd')
(u'36', u'Aft Raffles Blvd', u'Fort Rd JUNCTION/ECP')
(u'518', u'Fort Rd JUNCTION/ECP', u'Eastern Lagoon II')
(u'518', u'Eastern Lagoon II', u'Aft Bedok Sth Ave 1')
(u'518', u'Aft Bedok Sth Ave 1', u'Opp Kg Chai Chee CC')
(u'17A', u'Opp Kg Chai Chee CC', u'Blk 521')
(u'17A', u'Blk 521', u'Blk 516')
(u'17A', u'Blk 516', u'Opp Fengshan Pr Sch')
(u'18', u'Opp Fengshan Pr Sch', u'Blk 506')
(u'67', u'Blk 506', u'Opp Blk 761')
(u'67', u'Opp Blk 761', u'Opp The Clearwater Condo')
(u'22', u'Opp The Clearwater Condo', u'Opp Bedok Reform Trg Ctr')
(u'59', u'Opp Bedok Reform Trg Ctr', u'Opp SAFRA Tampines')
(u'59', u'Opp SAFRA Tampines', u'Blk 141')
(u'59', u'Blk 141', u'Opp The Holy Trinity Ch')
(u'59', u'Opp The Holy Trinity Ch', u'Blk 206')
(u'59', u'Blk 206', u'Tampines East CC')
(u'59', u'Tampines East CC', u'Tampines JC')
(u'59', u'Tampines JC', u'Blk 497D')
(u'59', u'Blk 497D', u'Blk 149A')
(u'59', u'Blk 149A', u'Blk 275')
(u'59', u'Blk 275', u'Aft Pasir Ris Dr 3')
(u'59', u'Aft Pasir Ris Dr 3', u'Opp Loyang Valley')
(u'59', u'Opp Loyang Valley', u'Loyang Ind Est')
(u'59', u'Loyang Ind Est', u'Bef Loyang Way')
(u'59', u'Bef Loyang Way', u'Opp Engine Test Facility')
(u'59', u'Opp Engine Test Facility', u'LP 80')
(u'59', u'LP 80', u'Bef Sch Of Commando')
(u'59', u'Bef Sch Of Commando', u'Bef Cranwell Rd')
(u'59', u'Bef Cranwell Rd', u'Opp Maranatha B-P Ch')
(u'59', u'Opp Maranatha B-P Ch', u'Aft Changi Golf Course')
(u'59', u'Aft Changi Golf Course', u'Blk 5')
(u'59', u'Blk 5', u'Changi Village Ter')
45 stops
No more 4N bus being used for part of the route! Instead, we take a different collection of buses.
Transfer Cost
As you may know, changing buses is not free! You always have to wait for the next bus to arrive, which certainly takes more time than staying on your current bus. The above trip-planner does not take this into account, and asks you to change buses every 2-5 stops, to try and minimize the distance traveled, but we actually want to minimize the time taken, which includes that spent changing buses. For that matter, apart from transfering, merely stopping at a bus stop has non-trivial cost! That too should be accounted for.
Let's consider bus transfers first. If I am at the Opp Orchard Stn stop, and I want to get to Grange Residences, I can take 111, 132, 7, or many other services. On the other hand, if I'm already on 111 when I reach Opp Orchard Stn, it would be foolish to change bus! Changing bus has a cost, and it should be part of my calculation when planning a trip.
The key insight here is that it doesn't just matter what stop you are at, but also what bus you are currently on. Thus the key of our graph should be a tuple of (current_stop, current_service):
@@ -56,8 +57,9 @@ for service, path in routes_map.items():
next_distance = next_route_stop["Distance"] or curr_distance
distance = next_distance - curr_distance
assert distance >= 0, (curr_route_stop, next_route_stop)
- graph[curr_route_stop["BusStopCode"]][next_route_stop["BusStopCode"]] = distance
+ curr_code = curr_route_stop["BusStopCode"]
+ next_code = next_route_stop["BusStopCode"]
+ graph[curr_code][(next_code, service)] = distance
print "Running BFS"
Here I'm changing the graph from:
{bus_stop_code: {adjacent_bus_stop_codes: distance_to_adjacent_bus_stop}}
to:
{bus_stop_code: {(adjacent_bus_stop_codes, service): distance_to_adjacent_bus_stop}}
The reason for this is that depending on what bus service we take to the next stop, it could have varying amounts of cost depending on what bus service I am currently on! Thus I have to model all possible services to the next adjacent stop, and not just the fact that "this stop is adjacent".
The next change would be to the dijkstras function:
@@ -67,36 +69,40 @@ def dijkstras(graph, start, end):
# maintain a queue of paths
queue = []
# push the first path into the queue
- heapq.heappush(queue, (0, [start]))
+ heapq.heappush(queue, (0, 0, 0, [(start, None)]))
while queue:
# get the first path from the queue
- (curr_distance, path) = heapq.heappop(queue)
+ (curr_cost, curr_distance, curr_transfers, path) = heapq.heappop(queue)
# get the last node from the path
- node = path[-1]
+ (node, curr_service) = path[-1]
+
# path found
if node == end:
- return path
- if node in seen:
+ return (curr_cost, curr_distance, curr_transfers, path)
+
+ if (node, curr_service) in seen:
continue
- seen.add(node)
+
+ seen.add((node, curr_service))
There are a few changes here:
-
There is a new set of cost variables, which is used to sort the elements in our Priority Queue instead of distance. We also maintain a curr_transfers variable keepign track of how many transfers we've done between bus services
-
The path we're storing includes the current service (or None) in addition to the bus stops
-
seen now contains tuples of (node, curr_service): as described earlier, how long it takes to get to adjacent stops depends not just on what stop we're at but what service we're on when we get there in case we need to transfer. That means even if we've seen a stop on a particular service, we can't immediately discount it in case there's some other bus service passing through that stop that could still be a viable route.
Next, we have the changes to the iteration from node to node:
# enumerate all adjacent nodes, construct a new path and push it into the queue
- for adjacent, distance in graph.get(node, {}).items():
- new_path = list(path)
- new_path.append(adjacent)
- heapq.heappush(queue, (distance + curr_distance, new_path))
-
+ for (adjacent, service), distance in graph.get(node, {}).items():
+ new_path = list(path)
+ new_path.append((adjacent, service))
+ new_distance = curr_distance + distance
+ new_cost = distance + curr_cost
+ new_transfers = curr_transfers
+ if curr_service != service:
+ new_cost += cost_per_transfer
+ new_transfers += 1
+ new_cost += cost_per_stop
+
+ heapq.heappush(queue, (new_cost, new_distance, new_transfers, new_path))
Here, we're replacing the old code which simply kept track of distance, with slightly more complex code that tracks three things:
- The
distance
- The
cost: includes the distance, and any additional cost we add due to transfers or passing through individual bus stops
- The number of
transfers, just for reporting at the end.
Lastly, we need to get the cost_per_transfer and cost_per_stop values from the user, which we can get using sys.argv:
haoyi-mbp:test haoyi$ git --no-pager diff
diff --git a/trip.py b/trip.py
index 7e931bf..de4da24 100644
--- a/trip.py
+++ b/trip.py
@@ -5,7 +5,8 @@ import pprint
start = sys.argv[1]
end = sys.argv[2]
current_time = int(sys.argv[3])
-
+cost_per_stop = float(sys.argv[4])
+cost_per_transfer = float(sys.argv[5])
print "loading JSON"
stops = json.loads(open("stops.json").read())
This allows us to get the cost_per_stop and cost_per_transfer from the user running the script, as floating point numbers. Intuitively, a value of e.g. 1.0 for cost_per_stop is saying "*consider each stop as taking additional time equivalent to driving 1km*", and similarly a value of 1.0 for cost_per_transfer.
And lastly, we need to modify our result-printing code to nicely display all data we're returning:
-path = dijstras(graph, stop_desc_map[start]["BusStopCode"], stop_desc_map[end]["BusStopCode"])
-def find_service(i):
- for (service, direction), route in routes_map.items():
- for j in range(len(route)-1):
- if path[i] == route[j]["BusStopCode"] and path[i+1] == route[j+1]["BusStopCode"]:
- return (
- service,
- stop_code_map[path[i]]["Description"],
- stop_code_map[path[i + 1]]["Description"]
- )
-
-for i in range(len(path) - 1):
- print find_service(i)
-print len(path), "stops"
+(cost, distance, transfers, path) = dijkstras(graph, stop_desc_map[start]["BusStopCode"], stop_desc_map[end]["BusStopCode"])
+
+for code, service in path:
+ print service, stop_code_map[code]["Description"]
+print len(path), "stops"
+print "cost", cost
+print "distance", distance, "km"
+print "transfers", transfers
Here we're getting rid of the hacky find_service function, since our modified dijkstras function now keeps track of which services it is taking out-of-the-box as path of the path it returns. We simply print:
- All the bus stops (identified by their
code) and services in path,
- How many stops the path took
- What it's final
cost is, including distance, transfers, stops
- How may kilometers long the route is
- How many transfers were taken
Completeness
And now we're done! We have a bus-trip-planner that we can run from the command line, give it start/end bus stops, time-of-day, and how much to penalize stopping at bus-stops or transferring buses, and it'll give you the best bus route it can find to make that trip. If you're not sure where the last series of patches and diffs has brought us, take a look at the Final Code
Although you haven't seen me run the final version of the code yet, I did in fact run it many times while debugging and figuring out why things went wrong. As for you, you can simply enjoy the interesting results that can be demonstrated by running this code, which is long enough that it deserves its own section of this post
Evaluation
We've made all the changes necessary to hit our original criteria! Let's run through a few cases with this script:
No Cost for Stops or Transfers
haoyi-mbp:test haoyi$ python trip.py "Opp Orchard Stn" "Changi Village Ter" 1700 0 0
loading JSON
Initializing tables
Initializing Graph
Running BFS
None Opp Orchard Stn
(u'14', 1) Opp Paterson Lodge
(u'14', 1) Bef Zion Full Gospel Ch
(u'54', 1) Opp ERC Inst
(u'195', 1) Airview Twr
(u'195', 1) Aft AA Ctr
(u'32', 2) Opp Mohd Sultan Rd
(u'32', 2) Opp Liang Ct
(u'195', 1) Opp Clarke Quay
(u'195', 1) Supreme Ct
(u'195', 1) Pan Pacific Hotel
(u'97', 1) Marina Ctr Ter
(u'36', 1) Aft Raffles Blvd
(u'36', 1) Fort Rd JUNCTION/ECP
(u'518', 1) Eastern Lagoon II
(u'518', 1) Aft Bedok Sth Ave 1
(u'518', 1) Opp Kg Chai Chee CC
(u'17', 1) Blk 521
(u'17', 1) Blk 516
(u'17A', 1) Opp Fengshan Pr Sch
(u'18', 1) Blk 506
(u'168', 1) Opp Blk 761
(u'168', 1) Opp The Clearwater Condo
(u'5', 2) Opp Bedok Reform Trg Ctr
(u'168', 1) Opp SAFRA Tampines
(u'518', 1) Blk 141
(u'518', 1) Opp The Holy Trinity Ch
(u'518', 1) Blk 206
(u'28', 2) Tampines East CC
(u'518', 1) Tampines JC
(u'12', 2) Blk 497D
(u'9', 1) Blk 149A
(u'9', 1) Blk 275
(u'59', 1) Aft Pasir Ris Dr 3
(u'19', 1) Opp Loyang Valley
(u'89', 1) Loyang Ind Est
(u'109', 1) Bef Loyang Way
(u'109', 1) Opp Engine Test Facility
(u'89', 1) LP 80
(u'109', 1) Bef Sch Of Commando
(u'109', 1) Bef Cranwell Rd
(u'2', 2) Opp Maranatha B-P Ch
(u'89', 1) Aft Changi Golf Course
(u'109', 1) Blk 5
(u'2', 2) Changi Village Ter
45 stops
cost 16.5
distance 16.5 km
transfers 29
Here, you can see that the algorithm picks a really short route - 16.5km - to get from Opp Orchard Stn to Changi Village Ter. However, because we input that transfers are cost 0, it takes all sorts of unnecessary transfers between services, 29 in total! However, the behavior changes once you introduce even a tiny cost for transfering buses.
- Note:
transfers counts how many distinct bus services you take; e.g. even if you take a single bus it counts as 1 "transfer". Another way of looking at it is your first bus counts as a trasnfer from "no service" to "some service". This is a technical detail that doesn't affect the algorithm or the trip-planning since every trip is equally affected, and you can easily - 1 from the final transfer count if you want to count only transfers-between-buses.
No Cost for Stops, Low Cost for Transfers
haoyi-mbp:test haoyi$ python trip.py "Opp Orchard Stn" "Changi Village Ter" 1700 0 0.1
loading JSON
Initializing tables
Initializing Graph
Running BFS
None Opp Orchard Stn
(u'14', 1) Opp Paterson Lodge
(u'54', 1) Bef Zion Full Gospel Ch
(u'54', 1) Opp ERC Inst
(u'195', 1) Airview Twr
(u'195', 1) Aft AA Ctr
(u'195', 1) Opp Mohd Sultan Rd
(u'195', 1) Opp Liang Ct
(u'195', 1) Opp Clarke Quay
(u'195', 1) Supreme Ct
(u'195', 1) Pan Pacific Hotel
(u'97', 1) Marina Ctr Ter
(u'36', 1) Aft Raffles Blvd
(u'36', 1) Fort Rd JUNCTION/ECP
(u'518', 1) Eastern Lagoon II
(u'518', 1) Aft Bedok Sth Ave 1
(u'518', 1) Opp Kg Chai Chee CC
(u'17', 1) Blk 521
(u'17', 1) Blk 516
(u'17', 1) Opp Fengshan Pr Sch
(u'18', 1) Blk 506
(u'18', 1) Opp Blk 761
(u'18', 1) Opp The Clearwater Condo
(u'18', 1) Opp Bedok Reform Trg Ctr
(u'18', 1) Opp SAFRA Tampines
(u'18', 1) Blk 141
(u'18', 1) Opp The Holy Trinity Ch
(u'18', 1) Blk 206
(u'59', 1) Tampines East CC
(u'59', 1) Tampines JC
(u'59', 1) Blk 497D
(u'59', 1) Blk 149A
(u'59', 1) Blk 275
(u'59', 1) Aft Pasir Ris Dr 3
(u'59', 1) Opp Loyang Valley
(u'59', 1) Loyang Ind Est
(u'59', 1) Bef Loyang Way
(u'59', 1) Opp Engine Test Facility
(u'59', 1) LP 80
(u'59', 1) Bef Sch Of Commando
(u'59', 1) Bef Cranwell Rd
(u'59', 1) Opp Maranatha B-P Ch
(u'59', 1) Aft Changi Golf Course
(u'59', 1) Blk 5
(u'59', 1) Changi Village Ter
45 stops
cost 17.4
distance 16.5 km
transfers 9
Here, we told the algorithm to count a transfer as an additional 0.1 kilometers traveled. Already that's enough to make it find a path with 9 transfers instead of 29. Note that the actual distance travelled hasn't changed at all: it's telling us to go through the exact same stops, just being smarter about staying on the same bus where possible
Realistically though, a bus transfer costs much more than 0.1km of travel: you can easily wait ~15 minutes for a bus when transferring!
No Cost for Stops, Moderate cost for transfers
Assuming a bus averages 20km/h, and a transfer has you waiting 15 minutes, we can count a transfer as equivalent to 5km traveled:
haoyi-mbp:test haoyi$ python trip.py "Opp Orchard Stn" "Changi Village Ter" 1700 0 5
loading JSON
Initializing tables
Initializing Graph
Running BFS
None Opp Orchard Stn
(u'36', 1) Opp Four Seasons Hotel
(u'36', 1) The Regent S`pore
(u'36', 1) Aft Tomlinson Rd
(u'36', 1) Delfi Orchard
(u'36', 1) Royal Thai Embassy
(u'36', 1) Tang Plaza
(u'36', 1) Opp Mandarin Orchard
(u'36', 1) Concorde Hotel S`pore
(u'36', 1) Dhoby Ghaut Stn
(u'36', 1) Rendezvous Grand Hotel
(u'36', 1) NTUC Income Ctr
(u'36', 1) Raffles Hotel
(u'36', 1) Suntec Convention Ctr
(u'36', 1) Opp Millenia Twr
(u'36', 1) Marina Ctr Ter
(u'36', 1) Aft Raffles Blvd
(u'36', 1) Fort Rd JUNCTION/ECP
(u'518', 1) Eastern Lagoon II
(u'518', 1) Aft Bedok Sth Ave 1
(u'518', 1) Opp Kg Chai Chee CC
(u'17', 1) Blk 521
(u'17', 1) Blk 516
(u'17', 1) Opp Fengshan Pr Sch
(u'17', 1) Blk 109
(u'17', 1) Blk 99
(u'17', 1) St. Anthony`s Cano Sch
(u'17', 1) Opp Goldbell Svc Ctr
(u'17', 1) SBST Bedok Bus Pk
(u'17', 1) Blk 3011
(u'17', 1) Blk 3012
(u'17', 1) Opp Changi General Hosp
(u'17', 1) Blk 141
(u'17', 1) Opp The Holy Trinity Ch
(u'17', 1) Blk 206
(u'17', 1) Tampines East CC
(u'17', 1) Tampines JC
(u'59', 1) Blk 497D
(u'59', 1) Blk 149A
(u'59', 1) Blk 275
(u'59', 1) Aft Pasir Ris Dr 3
(u'59', 1) Opp Loyang Valley
(u'59', 1) Loyang Ind Est
(u'59', 1) Bef Loyang Way
(u'59', 1) Opp Engine Test Facility
(u'59', 1) LP 80
(u'59', 1) Bef Sch Of Commando
(u'59', 1) Bef Cranwell Rd
(u'59', 1) Opp Maranatha B-P Ch
(u'59', 1) Aft Changi Golf Course
(u'59', 1) Blk 5
(u'59', 1) Changi Village Ter
52 stops
cost 39.3
distance 19.3 km
transfers 4
Here, you can see the actual distance-on-road traveled has risen from 16.5km to 19.3km: given the fact that transfers "cost 5km each", the trip planner is actively picking a longer journey to minimize the number of transfers. It's brought us down to 4 transfers.
If we wanted to, we could tell the trip planner to consider transfers "all important", and to avoid them at all costs. That will make it produce a route that minimizes the number of transfers at the expense of all else.
No Cost for Stops, Maximum Cost for Transfers
Here, we tell the trip planner that a transfer costs the same as driving 9999 kilometers. That's obviously an absurd number, and just needs to be high enough to make it outweigh all other considerations:
haoyi-mbp:test haoyi$ python trip.py "Opp Orchard Stn" "Changi Village Ter" 1700 0 9999
loading JSON
Initializing tables
Initializing Graph
Running BFS
None Opp Orchard Stn
(u'36', 1) Opp Four Seasons Hotel
(u'36', 1) The Regent S`pore
(u'36', 1) Aft Tomlinson Rd
(u'36', 1) Delfi Orchard
(u'36', 1) Royal Thai Embassy
(u'36', 1) Tang Plaza
(u'36', 1) Opp Mandarin Orchard
(u'36', 1) Concorde Hotel S`pore
(u'65', 2) Macdonald Hse
(u'65', 2) Sch of the Arts
(u'65', 2) Peace Ctr
(u'65', 2) Selegie Ctr
(u'65', 2) Tekka Ctr
(u'65', 2) Broadway Hotel
(u'65', 2) Sri Srinivasa Perumal Tp
(u'65', 2) Sri Vadapathira K Tp
(u'65', 2) Kwong Wai Shiu Hosp
(u'65', 2) Boon Keng Stn
(u'65', 2) Opp Bendemeer Pr Sch
(u'65', 2) St. Michael`s Pl
(u'65', 2) Aft Tai Thong Cres
(u'65', 2) Opp Gulab Bldg
(u'65', 2) Opp Cencon Bldg
(u'65', 2) Aljunied Pk
(u'65', 2) Aft Jln Anggerek
(u'65', 2) Blk 14
(u'65', 2) Blk 77
(u'65', 2) Blk 36
(u'65', 2) MacPherson Sec Sch
(u'65', 2) Blk 3019
(u'65', 2) Blk 3021
(u'65', 2) Blk 3023
(u'65', 2) Automobile Megamart
(u'65', 2) Blk 637
(u'65', 2) Blk 646
(u'65', 2) Blk 122
(u'65', 2) Blk 133
(u'65', 2) Blk 140
(u'65', 2) Aft Kaki Bt Ctr
(u'65', 2) Opp Blk 701
(u'65', 2) Blk 745
(u'65', 2) Opp Blk 716
(u'65', 2) Opp Waterfront Isle
(u'59', 1) Opp Waterfront Waves
(u'59', 1) Opp Waterfront Key
(u'59', 1) Opp The Clearwater Condo
(u'59', 1) Opp Bedok Reform Trg Ctr
(u'59', 1) Opp SAFRA Tampines
(u'59', 1) Blk 141
(u'59', 1) Opp The Holy Trinity Ch
(u'59', 1) Blk 206
(u'59', 1) Tampines East CC
(u'59', 1) Tampines JC
(u'59', 1) Blk 497D
(u'59', 1) Blk 149A
(u'59', 1) Blk 275
(u'59', 1) Aft Pasir Ris Dr 3
(u'59', 1) Opp Loyang Valley
(u'59', 1) Loyang Ind Est
(u'59', 1) Bef Loyang Way
(u'59', 1) Opp Engine Test Facility
(u'59', 1) LP 80
(u'59', 1) Bef Sch Of Commando
(u'59', 1) Bef Cranwell Rd
(u'59', 1) Opp Maranatha B-P Ch
(u'59', 1) Aft Changi Golf Course
(u'59', 1) Blk 5
(u'59', 1) Changi Village Ter
69 stops
cost 30023.9
distance 26.9 km
transfers 3
As you can see, it's managed to bring the number of transfers down from 4 to 3, albeit at a cost of increasing the distance traveled from 19.3km to 26.9km. Further increases to the cost of transfers does nothing: this is already the minimum number of transfers possible!
Maximum Cost for Stops, Low Cost for Transfers
Apart from transfers, the other thing we can tell our trip planner to weigh is the number of bus stops crossed. Buses take time to pull into each stop, and load/unload passengers. What if wanted it to at-all-costs minimize the number of bus stops traveled? In that case we can give an absurd cost of 9999 for each bus stop, and leave a low cost of 0.1 per transfer just to keep it from needlessly switching buses:
haoyi-mbp:test haoyi$ python trip.py "Opp Orchard Stn" "Changi Village Ter" 1700 9999 0.1
loading JSON
Initializing tables
Initializing Graph
Running BFS
None Opp Orchard Stn
(u'36', 1) Opp Four Seasons Hotel
(u'36', 1) The Regent S`pore
(u'36', 1) Aft Tomlinson Rd
(u'132', 2) Delfi Orchard
(u'132', 2) Royal Thai Embassy
(u'132', 2) Thong Teck Bldg
(u'190', 2) Raffles Girls` Sch
(u'190', 2) Chelsea Gdn Condo
(u'190', 2) Opp Met YMCA
(u'190', 2) Opp Stevens Ct
(u'190', 2) Raffles Town Club
(u'190', 2) Express
(u'858', 1) Express
(u'858', 1) Airport Police Stn
(u'53', 1) Bef Changi Airport PTB3
(u'53', 1) Changi Airport PTB3
(u'53', 1) Changi Airport PTB1
(u'53', 1) Changi Airport PTB2
(u'53', 1) Aft Changi Airport PTB2
(u'53', 1) Near SATS Flight Kitchen
(u'53', 1) At Track 33 Int
(u'53', 1) Blk 149A
(u'59', 1) Blk 275
(u'59', 1) Aft Pasir Ris Dr 3
(u'59', 1) Opp Loyang Valley
(u'59', 1) Loyang Ind Est
(u'59', 1) Bef Loyang Way
(u'59', 1) Opp Engine Test Facility
(u'59', 1) LP 80
(u'59', 1) Bef Sch Of Commando
(u'59', 1) Bef Cranwell Rd
(u'59', 1) Opp Maranatha B-P Ch
(u'59', 1) Aft Changi Golf Course
(u'59', 1) Blk 5
(u'59', 1) Changi Village Ter
36 stops
cost 350047.7
distance 82.1 km
transfers 6
Here, you can see that the trip planner has found a route that has 36 bus stops instead of 45, but in the process increases the length of the route from 16.5km to 82.1km! Obviously this is not a route that you would want to do in real life, but it is an interesting demonstration that depending on what you tell the trip planner to focus on, you could get very different results. If you tell it that the number of bus stops is the most important thing, much more than anything else (cost_per_stop = 9999) then we can't be surprised if it finds a route optimizing for the number of stops, sacrificing the distance-traveled in the process!
Other Trips
To properly evaluate the trip-planner, let's throw it a few more trips to plan, that we already know the answer to, to see how it fares!
- Note: For these we'll use "reasonable" costs for bus-stops and bus-transfers: counting each bus stop as equivalent to traveling 0.5km, and each bus transfer as traveling 5km. With an average speed of 20km/h, that's equivalent to saying each stop is for 90s and each bus transfer takes 15 minutes; not exact, but roughly the correct order of magnitude.
For example, can it find the short direct bus from Grange Residences to Redhill Stn?
haoyi-mbp:test haoyi$ python trip.py "Grange Residences" "Redhill Stn" 1500 0.5 5
loading JSON
Initializing tables
Initializing Graph
Running BFS
None Grange Residences
(u'132', 1) Opp British High Comm
(u'132', 1) Bef Rochalie Dr
(u'132', 1) Bef Chatsworth Rd
(u'132', 1) Crescent Girls` Sch
(u'132', 1) Redhill Stn
6 stops
cost 9.8
distance 2.3 km
transfers 1
How about the long direct bus between Ghim Moh Terminal and The Esplanade?
haoyi-mbp:test haoyi$ python trip.py "Ghim Moh Ter" "The Esplanade" 1500 0.5 5
loading JSON
Initializing tables
Initializing Graph
Running BFS
None Ghim Moh Ter
(u'111', 1) Blk 12
(u'111', 1) Blk 43
(u'111', 1) Blk 8
(u'111', 1) C`wealth Stn
(u'111', 1) Aft Ch Of Our Saviour
(u'111', 1) Queenstown Stn
(u'111', 1) Blk 53A CP
(u'111', 1) Opp SM Motors Ctr
(u'111', 1) Opp SIS Bldg
(u'111', 1) Aft Margaret Dr
(u'111', 1) Opp Chatsworth Rd
(u'111', 1) Aft Rochalie Dr
(u'111', 1) British High Comm
(u'111', 1) Aft Tomlinson Rd
(u'111', 1) Delfi Orchard
(u'111', 1) Royal Thai Embassy
(u'111', 1) Lucky Plaza
(u'111', 1) Midpoint Orchard
(u'111', 1) Concorde Hotel S`pore
(u'111', 1) Dhoby Ghaut Stn
(u'111', 1) Rendezvous Grand Hotel
(u'111', 1) NTUC Income Ctr
(u'111', 1) Raffles Hotel
(u'111', 1) Suntec Convention Ctr
(u'111', 1) Opp Millenia Twr
(u'111', 1) Opp The Ritz-Carlton
(u'111', 1) Seating Gallery
(u'111', 1) The Esplanade
29 stops
cost 31.1
distance 12.1 km
transfers 1
How about the 1-transfer necessary to go from my old school ACS(I) to Orchard MRT?
haoyi-mbp:test haoyi$ python trip.py "Opp ACS Boarding Sch" "Orchard Stn" 1500 0.5 5
loading JSON
Initializing tables
Initializing Graph
Running BFS
None Opp ACS Boarding Sch
(u'33', 2) Fairfield Meth Pr Sch
(u'33', 2) Ayer Rajah Ind Est
(u'33', 2) Opp PSB Science Pk Bldg
(u'33', 2) Opp Normanton Pk
(u'33', 2) Alexandra Hosp
(u'33', 2) Anchorpoint
(u'33', 2) Opp Lea Hin Hardware Fty
(u'33', 2) Opp SM Motors Ctr
(u'33', 2) Redhill Stn
(u'33', 2) Delta Swim Cplx
(u'33', 2) Blk 104A CP
(u'33', 2) Tiong Bahru Pk
(u'33', 2) Tiong Bahru Plaza
(u'33', 2) Blk 1
(u'33', 2) EtonHouse Pre-Sch
(u'33', 2) Outram Pk Stn
(u'33', 2) People`s Pk Cplx
(u'143', 2) Opp Subordinate Ct
(u'143', 2) Shell HSE
(u'143', 2) Aft River Valley Rd
(u'143', 2) Opp Haw Par Glass Twr
(u'143', 2) Winsland Hse
(u'143', 2) Somerset Stn
(u'143', 2) Opp Ngee Ann City
(u'143', 2) Orchard Stn
26 stops
cost 35.0
distance 12.5 km
transfers 2
All three routes look correct. Seems like the trip-planner works!
Limitations
It's worth remembering our original problem statement, and spelling out some expected/implicit limitations of the code we wrote:
-
This does not handle multi-modal transport: it doesn't know how to plan trips including trains, or even walking, meaning that even if a 5-minute walk could save an hour of busing this trip-planner won't know about it
-
It's treatment of bus-transfers is crude; it treats all transfers as equally costly, while in reality there is information available about how frequently buses arrive at each stop, and even exactly what times the next few buses are expected to arrive via the /BusArrival API. This allows you to pull down bus arrival information for any bus service at any (or every!) bus stop on the island! We could use this to make the algorithm optimize for this waiting time, finding routes that "line up" transfers and minimizing the time you spend waiting at a stop.
-
It's understanding of Time is simplistic: it simply filters out buses which are unavailable when you start the trip, not understanding that as the trip progresses more buses may become unavailable. It does not understand the fact that bus frequencies, and thus the expected wait for a transfer, changes during the morning/evening peak hours and on weekends. All this data is available in the various APIs, we would just need to put it to use.
-
It's a command-line application. More work would be needed to turn it into a mobile app, or a website, or a desktop widget. Nevertheless, the work to make mobile apps, websites, or desktop widgets is pretty orthogonal to working with these datasets or APIs, and you can learn those skills elsewhere.
-
The app measures distance traveled, but does not take into account the speed at which you're traveling along each road! That data is actually all freely available from the LTA Data Mall from the /TrafficSpeedBandSet endpoint, in real-time (i.e. what is the speed right now). While not very precise (it seems to have only 4 buckets 0-20, 20-40, 40-60, 60+) it would be enough for a trip-planner to use to plan routes avoiding major congestion
Conclusion
In this post, we've made a rudimentary bus-trip-planner from first principles:
-
Exploring APIs related to the Singapore Smart Nation initiative. We've broadly browsed and surveyed the landscape of possibilities, and seen what the most prominent and well-published APIs in that space are.
-
Browsing, selecting and downloading data from the LTA Data Mall API. We've fidgeted with API credentials, dug through weird PDF documentation on awkward websites, and done all that's necessary to get the data we want
-
Exploring it in IPython to see what's there and validating some basic assumptions. We've worked with data too large to browse manually, and seen how you can use the IPython shell to understand it quickly in-bulk, in a matter of seconds asking questions of quantities of data far-too-large to answer manually. We've found peculiarities, missing datapoints, and outright mistakes in the dataset, and learned to deal with them and work around them.
-
Written standalone application that can be run using this data. It might not be pretty - it's a command-line program after all! - but it works, and is something you can package up and run on some server, on your phone, or on your friends' laptops.
-
Made use of basic algorithms to turn it into a useful, flexible, and powerful trip-planner. While almost every programmer learns these algorithms in school, we've used them in a concrete way on concrete datasets in order to plan trips across Singapore.
In the process, we've written about 150 lines of Python, the final code being available below. Although there's no way we can compete with Google Maps or gothere.sg, it's not a bad outcome for 150 lines of code! Hopefully this post has shown how easy it is to make "something useful" with the datasets and APIs being exposed as part of the Singapore Smart Nation initiative, as well as how "freshman year" algorithms and computer-science can be used to accomplish real work and make cool, useful things.
Let me know what you think in the comments below!
Final Code
Here's the final output of this whole exercise. Everything should be runnable except for installing Python/Requests/IPython and needing to swap in your own AccountKey and UniqueUserId before running.
run.py
This script makes it easy for you to download various data sets from the LTA Data Mall and saves them to JSON files. You can also import it from the IPython shell and download stuff interactively.
As written, it downloads information on bus stops, bus services, and bus routes, and dumps them all into JSON files for you to use later. It takes a minute or two to run, depending on how fast your internet connection is. If you want to see it making progress, put a print len(results) inside the while loop and you'll be able to see how many items it's fetched as it happens.
import requests
import json
headers = {
'AccountKey': 'rmgDEFTiRRfcNeD8GbHqf8==',
'UniqueUserID': '8ecabd56-08a2-e843-0a7a-9944dccf124a',
'accept': 'application/json'
}
def fetch_all(url):
results = []
while True:
new_results = requests.get(
url,
headers=headers,
params={'$skip': len(results)}
).json()['value']
if new_results == []:
break
else:
results += new_results
return results
if __name__ == "__main__":
stops = fetch_all("http://datamall2.mytransport.sg/ltaodataservice/BusStops")
with open("stops.json", "w") as f:
f.write(json.dumps(stops))
services = fetch_all("http://datamall2.mytransport.sg/ltaodataservice/BusServices")
with open("services.json", "w") as f:
f.write(json.dumps(services))
routes = fetch_all("http://datamall2.mytransport.sg/ltaodataservice/BusRoutes")
with open("routes.json", "w") as f:
f.write(json.dumps(routes))
trip.py
This file lets you ask for a route between two named bus stops, optimized for some parameters. Called via
python trip.py "<first-stop>" "<last-stop>" <time> <cost-per-stop> <cost-per-transfer>
python trip.py "Opp Orchard Stn" "Changi Village Ter" 1700 0.5 5.0
You can run this code can be run against the data downloaded by run.py, or you can skip that step, directly download the Datasets I prepared earlier and use those.
Internally, it loads three JSON files that we downloaded earlier in run.py as part of our Datasets, pre-processes them a bit into more convenient data structures (stop_desc_map, stop_code_map, routes_map and graph) and then feeds the graph, along with user-input on how expensive it is to traversing a bus stop or make a transfer, into Dijkstra's Algorithm to find the "least costly" route given those criteria. At the end, it prints out that route (what stops/services it took) along with some aggregate data (distance, number-of-transfers) about the entire route.
import sys
import json
import pprint
start = sys.argv[1]
end = sys.argv[2]
current_time = int(sys.argv[3])
cost_per_stop = float(sys.argv[4])
cost_per_transfer = float(sys.argv[5])
print "loading JSON"
stops = json.loads(open("stops.json").read())
services = json.loads(open("services.json").read())
routes = json.loads(open("routes.json").read())
print "Initializing tables"
stop_desc_map = {stop["Description"]: stop for stop in stops}
stop_code_map = {stop["BusStopCode"]: stop for stop in stops}
routes_map = {}
for route in routes:
try:
first_bus = int(route["WD_FirstBus"])
last_bus = int(route["WD_LastBus"])
except:
continue
if first_bus <= last_bus:
if not (first_bus <= current_time <= last_bus):
continue
if first_bus > last_bus:
if (last_bus <= current_time <= first_bus):
continue
key = (route["ServiceNo"], route["Direction"])
if key not in routes_map:
routes_map[key] = []
# hack around broken data
if (route["StopSequence"] == 4
and route["Distance"] == 9.1
and key == ("34", 1)):
route["StopSequence"] = 14
routes_map[key] += [route]
print "Initializing Graph"
graph = {}
for service, path in routes_map.items():
# hack around broken data
path.sort(key = lambda r: r["StopSequence"])
for route_index in range(len(path) - 1):
key = path[route_index]["BusStopCode"]
if key not in graph:
graph[key] = {}
curr_route_stop = path[route_index]
next_route_stop = path[route_index + 1]
curr_distance = curr_route_stop["Distance"] or 0
next_distance = next_route_stop["Distance"] or curr_distance
distance = next_distance - curr_distance
assert distance >= 0, (curr_route_stop, next_route_stop)
curr_code = curr_route_stop["BusStopCode"]
next_code = next_route_stop["BusStopCode"]
graph[curr_code][(next_code, service)] = distance
print "Running BFS"
def dijkstras(graph, start, end):
import heapq
seen = set()
# maintain a queue of paths
queue = []
# push the first path into the queue
heapq.heappush(queue, (0, 0, 0, [(start, None)]))
while queue:
# get the first path from the queue
(curr_cost, curr_distance, curr_transfers, path) = heapq.heappop(queue)
# get the last node from the path
(node, curr_service) = path[-1]
# path found
if node == end:
return (curr_cost, curr_distance, curr_transfers, path)
if (node, curr_service) in seen:
continue
seen.add((node, curr_service))
# enumerate all adjacent nodes, construct a new path and push it into the queue
for (adjacent, service), distance in graph.get(node, {}).items():
new_path = list(path)
new_path.append((adjacent, service))
new_distance = curr_distance + distance
new_cost = distance + curr_cost
new_transfers = curr_transfers
if curr_service != service:
new_cost += cost_per_transfer
new_transfers += 1
new_cost += cost_per_stop
heapq.heappush(queue, (new_cost, new_distance, new_transfers, new_path))
(cost, distance, transfers, path) = dijkstras(graph, stop_desc_map[start]["BusStopCode"], stop_desc_map[end]["BusStopCode"])
for code, service in path:
print service, stop_code_map[code]["Description"]
print len(path), "stops"
print "cost", cost
print "distance", distance, "km"
print "transfers", transfers
Datasets
Here are the JSON data-sets that I downloaded to use offline as part of Caching. No doubt these files will get stale over time, possible next week, probably next month, definitely in the next year. Nevertheless, there's value in keeping
While you can always re-download them using run.py, doing so is slow, and if the API changes or gets shut down, these files will remain here so people can still follow along.
About the Author: Haoyi is a software engineer, and the author of many open-source Scala tools such as the Ammonite REPL and the Mill Build Tool. If you enjoyed the contents on this blog, you may also enjoy Haoyi's book Hands-on Scala Programming